

R入門講座 チュートリアル編
環境構築
RとRstudio
R
Rとは、統計解析用のプログラム言語・ツールです。Rやパッケージ(Rの拡張機能)はインターネット上で公開されているので、無償で利用できます。
Rを使うメリット
・無料で利用できること
・様々な手法がパッケージとして公開されており、応用範囲が広いこと
・他のプログラミング言語と比べて、記述するコード量が少ないこと
・分析の途中結果を追えること
Rの弱点
・コマンドラインでの作業になるため、直感的な作業ができないこと
・他のプログラミング言語と比べて、処理速度が遅いこと
Rに関する情報源
・Rに関する情報公開を目的としたwiki:http://www.okadajp.org/RWiki/
・R言語に特化した検索サイト:http://rseek.org/
・Rによる統計処理:http://aoki2.si.gunma-u.ac.jp/R/
・R tips:http://www.is.titech.ac.jp/~mase/Rtips.html
RStudio
RStudioとは、Rを使うための統合開発環境で、Rにまつわるファイル、関数、変数、パッケージ、図などを管理することができるソフトです。RStudioは計算部分にR本体を使いますので、RStudioを使う場合は、R本体とRStudioをインストールする必要があります。RStudioの操作方法については後述します。
インスト-ル
R本体とRStudioのインストールを行います。RStudioのインストールには、先にR本体がインストールされている必要があるので、R本体 → RStudioの順でインストール作業を進めてください。
Rのインストール
Rのインストーラを下記サイトよりダウンロードし、インストーラを立ち上げてインストールしてください。http://cran.ism.ac.jp/
RSutudioのインストール
R Studio のサイト(https://www.rstudio.com/products/rstudio/download/)から、各自のOSに合ったものをダウンロードし、インストールしてください。
RStudioの基本操作
RStudioのパネル(画面)機能紹介
RStudioの画面構成について解説します。RStudioのアイコンをクリックし、RStudioを立ち上げてください。次に、メニューから[ File ]→[ R Script ] を選択します。
下図のような4つのパネルで構成されている画面が、基本画面になります。
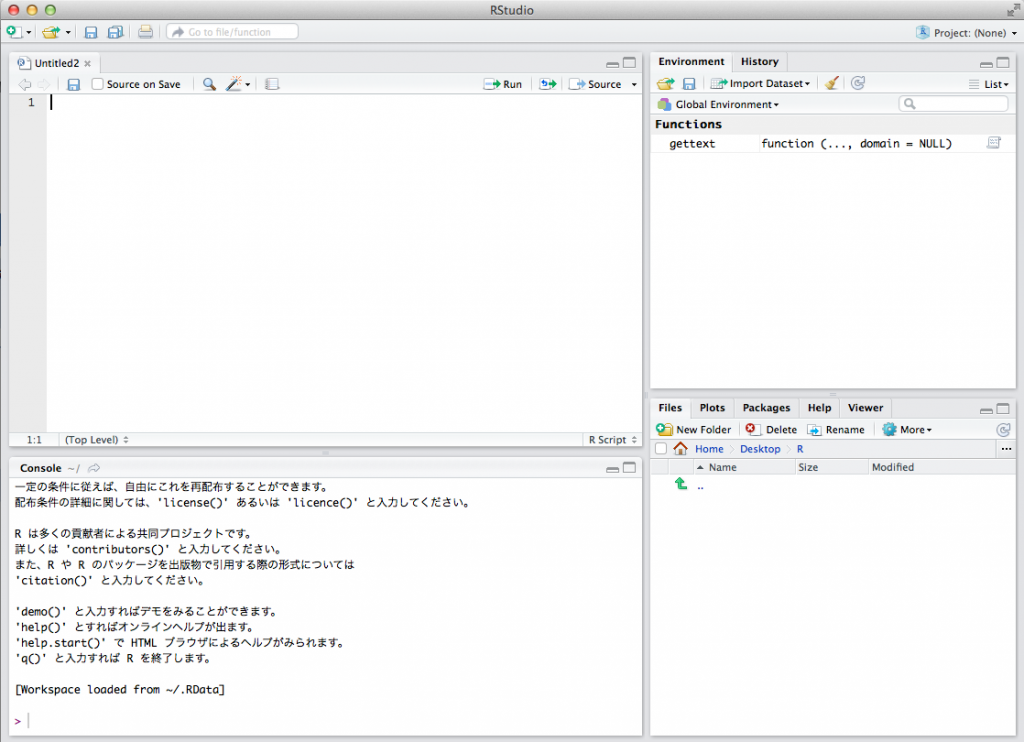
Souece editor, data view パネル(左上)
・Source editor:Rのコードを記述する箇所。選択した範囲を[Ctrl] + [Enter]で実行することきます。
・data view:右上のWorkspaceパネルや、右下のFileパネルで選択したデータの中身を表示させます。
Console パネル(左下)
コマンドの入力と分析結果の出力画面になります。
Workspace パネル(右上)
使用しているオブジェクトの型が表示され、選択すると中身を確認することができます。
File, Plots, Packages, Help, Viewer パネル(右下)
・Files:フォルダ内のファイル一覧を表示する画面です。
・Plots:グラフの描画結果が出力される画面です。
・Packages:インストール済みのパッケージ一覧の表示と、読み込みたいパッケージを選択する画面です。
・Help:ヘルプが表示される画面です。
・Viewer:RStudioのローカルコンテンツを表示する画面です。
新規プロジェクト作成手順
RStudio では、コードやデータファイルを「プロジェクト」としてまとめます。プロジェクトを作成するには、メニューの[ Project] →「Create new projec」を選択し、ファイルを置いておくフォルダを指定します。以降は、先ほど選択したフォルダの中に作られる「.proj」 ファイルを選択することでプロジェクトを続けることができるようになります。
説明のために、プロジェクトフォルダを[ R_lesson]とします。このR_lessonフォルダ内に、プロジェクトファイル[ R_lesson.proj ]、コードファイル[ R_lesson.R ]、データ用フォルダ[ dat ]を配置します。
|
コードファイルは、メニューから[ File ]→[ R Script ] を選択して新規にコードファイルを作成し、保存することで作成できます。
パッケージの設定
パッケージとは、R本体とは別の拡張機能です。パッケージは、世界中のユーザが開発しているもので、さまざまな機能が提供されており公開されているものは自由に使うことができます。また、R本体とは別にインストールする必要があります。
パッケージのインストールはinstall.packages()関数で、読み込みはlibrary()関数で実行できます。1周目の方は読み飛ばしてください。詳しい解説は後述します。
また、文章中のコードでは「>」の行がプログラム部分、「>」が無い行は出力結果です。
> install.packages(“hogehoge”)
> library(hogehoge)
データの読み込み
RはデータベースやAPI、Excel、HTML、CSVファイルなどさまざまなものからデータを読み込むことができます。ここでは汎用性の高いCSVファイルからのデータの読み込みについて解説します。
CSVファイルからのデータの読み込み
データフォルダ[dat] 内に、lesson_data.csvが置いてあるとして、このファイルからデータを読み込み、変数datに代入します。
CSVファイルからデータを読み込むにはread.csv()関数を使います。()の中には引数として様々なオプションを設定することができます。また、Rでは改行は無視されます。
> dat <- read.csv(“dat/lesson_data.csv”,
> header = T,
> stringsAsFactors = F,
> fileEncoding = “SJIS”)
・dat <- :Rでは「<-」で変数に値や関数を代入することができます。
・”dat/lesson_data.csv”:読み込むファイルのパスを指定します。プロジェクトフォルダからの相対パスを指定します。
・header = T,:データファイルの1行目を列の見出しとして使用する場合はT ( TRUEの略)、使用しない場合はF (FALSEの略)を指定します。
・stringsAsFactors = F:読み込まれるデータをファクターとして読み込む場合はT、そうでない場合はFを指定します。ファクターについては後で解説します。通常はFを設定してファクターとして読み込まずに、必要に応じてファクターに変換します。
・fileEncoding = “SJIS”:読み込むファイルのエンコーディングを指定します。Excelで作成したファイルで日本語を含む場合は、”SJIS”を指定することで文字化けを回避できます。
データの型とデータ構造
データの型
Rで扱うデータの型について解説します。ここで解説するもの以外にも複素数や時系列を扱うものがありますが、本稿の範囲をこえるため省略します。
実数(numeric)
一般的な数字。小数を含むdouble型と、整数のinteger型に細分化できる。
文字列(character)
文字列。
論理値(logical)
論理値でTRUEとFALSEの2値。数字ではTRUE = 1、FALSE = 0に対応する。省略してTとFで記述できる。
ファクター(factor)
因子。大、中、小など文字列として扱うより、カテゴリー分けに使いたい場合に指定する。デフォルトでは辞書順に並ぶ。
データ構造
変数にどのような構造でデータが入っているか、Rで扱えるデータ構造の主要なものについて解説します。
ベクトル
同じデータ型のデータを並べたもの。ベクトルを作成するにはc( )関数を使います。
> x <- c(1, 2, 3,,4)
> x
[1] 1 2 3 4
リスト
さまざまなベクトルを1つのデータセットとしてまとめたもの。異なるデータ型のベクトルもまとめることができきます。また、多くの分析用関数の分析結果はこのデータ構造で出力されます。リストの作成はlist()関数を使います。
> L1 <- list(c(1, 2), c(“a”, “b”))
>L1
[[1]]
[1] 1 2
[[2]]
[1] “a” “b”
データフレーム
リストの1種で、各ベクトルの要素数が同じもの(要は表形式)。先述のread.csv()関数で読み込まれたものは、このデータ構造で保持されます。データフレームの作成はdata.frame()関数を使います。
> dat <- data.frame(c(1, 2), c(“a”, “b”)
> dat
c.1..2. c..a….b..
1 1 a
2 2 b
データ整形操作
集計用関数
Rでは、合計や平均をはじめとした集計用関数が提供されています。
サンプルデータ
> x <- c(6, 7, 8, 9, 10)
合計
> sum(x)
[1] 40
平均
> mean(x)
[1] 8
中央値
> median(x)
[1] 8
要素数
> length(x)
[1] 5
データの抽出方法
データ構造の中からデータを抽出する方法について解説します。
ベクトル
ベクトルの添字に抽出したい要素の番号(デフォルトでは1から順ふられる)を指定することで、データを抽出できます。次のコードは2つ目の要素を抽出した例です。
> x <- c(6, 7, 8, 9, 10)
> x[2]
[1] 7
データフレーム
データフレームでは、特定の行や列を抽出することができます。ここではサンプルデータとしてRに組み込まれているデータセット[ iris ]を使用します。
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
head()関数はデータを確認するための関数で、データの上6行を返します。
・列番号を指定して抽出する
> iris[, 2]
[1] 3.5 3.0 3.2 3.1 3.6 3.9 3.4 …(長いので省略)
・行番号を指定して抽出する
> iris[2,]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
2 4.9 3 1.4 0.2 setosa
・列名を指定して抽出する(データセット$列名)
> iris$Sepal.Length
[1] 5.1 4.9 4.7 4.6 5.0 5.4 4.6 5.0 …(長いので省略)
・条件に該当するデータを抽出する
列Speciesの値がvirginicaのデータを抽出する
> iris[iris$Species == “virginica”,]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
101 6.3 3.3 6.0 2.5 virginica
102 5.8 2.7 5.1 1.9 virginica
103 7.1 3.0 5.9 2.1 virginica
(長いので省略)
関数の利用
Rではさまざまな統計解析用の関数が提供されています。
関数のヘルプを表示する
各関数の使い方(help)は、次のコードで表示させることができます。
> help(関数名)
関数を利用する(回帰分析の例)
回帰分析用のlm()関数を例に関数の使い方について解説します。ここではサンプルデータとしてRに組み込まれているデータセット[ cars ]を使用します。
> cars.lm <- lm(dist ~ speed, data = cars)
> summary(cars.lm)
Call:
lm(formula = dist ~ speed, data = cars)
Residuals:
Min 1Q Median 3Q Max
-29.069 -9.525 -2.272 9.215 43.201
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -17.5791 6.7584 -2.601 0.0123 *
speed 3.9324 0.4155 9.464 1.49e-12 ***
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
コードの解説
・cars.lm <- :分析結果を代入します。
・lm(dist ~ speed, data = cars):回帰分析の本体部分。y = ax + bのyにdist、xにspeedが該当し、+ b の部分は省略。data にはデータセットを指定します。
・summary(cars.lm):分析結果概要を表示します。
分析結果(dist = 3.9324 ×speed – 17.5791)の解釈
・InterceptのEstimateが切片の推定値(- 17.5791)、P値が0.0123
・speedのEstimateが回帰係数(3.9324)、P値が1.49e-12
一般的にP値が0.05以下の場合は、統計的に有意(つまりOK)と解釈ができます。したがって、この結果は統計的に有意と解釈できます。
グラフの描写
Rでのグラフの描写について解説します。サンプルデータとして先ほどの[ iris]を使います。
ちなみにirisとは植物のアヤメです。Sepal.Length はがく片の長さ、Pepal.Width はがく片の幅、Petal.Length は花びらの長さ、Petal.Width は花びらの幅を意味します。Speciesはアヤメの3つの種類(セトサ、バージカラー、バージニカ)です。
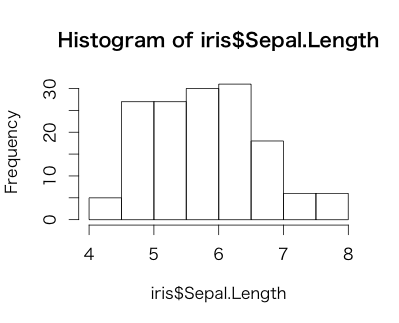
ヒストグラムの作成
> hist(iris$Sepal.Length)
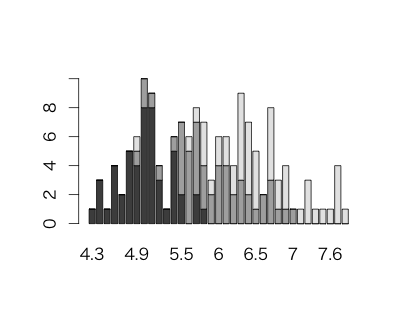
棒グラフの作成
> barplot(table(iris$Species, iris$Sepal.Length))
散布図の作成
> plot(iris$Sepal.Length,iris$Sepal.Width)
折れ線グラフの作成
> plot(iris$Sepal.Length,type=”l”)
type=”l”を指定することで、折れ線グラフを描写することができます。
レポートの作成
HTMLファイルでRのコードと分析結果を出力する
下図の赤で囲った箇所の本のようなアイコンをクリックすることで、Source editor(左上のパネル)に記述されたコードとその実行結果をHTMLファイルとして出力することができます。