- 2016年9月5日
なるべく情報を落とさずに少数の変数(次元)に要約する分析手法です。
複数項目のデータを2次元の図で視覚化する場合によく使われます。また、調査項目ごとの指向性の強さや関連性を定量化・視覚化することにも使われます。
類似する分析手法にコレスポンデンス分析があります。
属性などのカテゴリカルデータを含むデータを分析する際は、コレスポンデンス分析を使用します。
主な適用場面は、顧客の嗜好性や行動に基づくセグメンテーション、ポジショニングマップの作成が挙げられます。
■分析例:どのようなセグメントに分けることができるか?
アルゴリズム
左図のように2つの変数(x軸とy軸)で表されるデータがあります。これらを左図の斜め線(合成変数)の座標に変換し、回転すると右図になります。ここでは2変数を1変数に縮約しました。このようにして変数を合成します。
用語
・主成分(固有ベクトル):合成した変数
・主成分得点:データと主成分を掛けあわせたもの。
・固有値:主成分の情報の多少(主成分に対するデータのバラツキの大きさ)。もっとも大きい固有値に対応する主成分を第一主成分、その次に大きい固有値に対応する主成分を第2主成分と呼ぶ。
・寄与率:各主成分がデータ全体に対しどれくらいの情報を持っているかは、その主成分が対応する固有値が固有値全体に締めている割合で説明できる。この割合を寄与率、その寄与率を累積したものを累積寄与率と呼ぶ
図の解釈
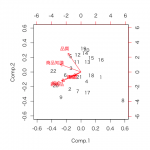
一番上のグラフは主成分分析の分析結果を図示したものです。
・矢印の長さ:嗜好性の強さ(長いほどバラツキがある、違いがある)。
・矢印の向き:向きが近いほど項目間の関連性が強い。
・プロット(点):類似度の高い調査対象ほど近くにプロットされる。
- 2016年9月5日
時系列データとは、対象の指標が時間に依存しているデータのことです。
例えば、株価や売上、体重など、前の観測値を基準に増減を調べるようなデータになります。
では、あなたが毎日サイコロを振って記録したとします。このサイコロの出た目の記録は時系列データでしょうか?
答えは「No」です。
前日にどんな目が出ようが、サイコロの目のそれぞれが出る確率は6分の1です(通常のサイコロでは)。つまり、前の観測値と次の観測値に関連性がないので、ここでの時系列データでないことになります。
解析時の計算や集計処理の方法が他のデータとは異なるところがあります。
時系列データを使って分析する目的は、変化のパターンを見つけることや、変化のきっかけ、変化の幅を把握することです。
大抵の場合、折れ線グラフを描画することでことたりるかと思います。
- 2016年9月5日
分析の基準になる変数が最も偏る切り口でグループ分けをし、以降、各グループに対しても同じ操作を繰り返します。
最も偏る切り口が分類の基準への影響が大きいと判断できます。
また、各グループに含まれる変数の割合により予測ルール(モデル)を構築します。予測したい対象がどのグループに属するかがわかれば、先の予測ルールにより予測ができます。
主な適用場面として、会員になりやすい顧客の特徴を調べる、離脱しやすいページを特定する等が挙げられます。
また、目的変数は質的データだけでなく、量的データでも同様に分析できます。目的変数が量的データの場合は、回帰木と呼ばれます。
さらに、この決定木の概念は機械学習を習得するための基礎になります。
■分析例:どのような人が会員になりやすいか?
アルゴリズム
目的変数が会員、非会員の例で決定木の構築方法(アルゴリズム)を考えてみます。
分割前のデータ(図では一番上の丸の中)に対して、ある説明変数で分割して分割後の目的変数の偏りぐわい(ジニ係数)を計算します。
目的変数に影響を大きく与えている切り口(説明変数)で分割した場合は、ジニ係数は小さくなり、分割した片方で会員の割合が大きくなり、もう片方で非会員の割合が大きくなります。
これをすべての説明変数で実行し、一番ジニ係数が小さくなる説明変数(分割基準)を見つけます。分割した後のグループに対しても同じことを実行していけば、最終的にツリー構造のルールが得られます。
- 2016年9月5日
商品レビューや口コミ、問い合わせ、クレーム等顧客の声を分析するために、「テキストマイニング」といわれる手法があります。
テキストマイニングでは、文章などの定性的なデータを定量的なデータに変換し、様々な解析手法を適用します。
文章等の定性的なデータを人海戦術で処理していたものを、分析を用いて自働化・半自動化することで、業務効率向上による人件費の削減や、システム化が可能になります。
テキストマイニングで用いられる手法に「形態素解析」「ワードカウンティング」「共起分析」などがあります。
形態素解析は、機械が単語を認識するための手法で、文章を単語などに分けます。
ワードカウンティングでは、形態素解析で切り分けられた単語の各文章中における出現頻度を集計します。
アウトプットはクロス集計表をイメージしてください。この集計表では定量データに変換されているため、さまざまな解析手法を適用することができます。
共起分析では、単語同士のつながりを分析します。例えば、同じ文章中に出現しやすい単語をネットワークで表現します。
「R」に関連するTwitterを共起分析した例
- 2016年9月5日
コレスポンデンス分析は、ポジショニングを直感的に理解できるマップを提供します。
実数だけでなく、カテゴリーデータも分析できるため、適用範囲が広い分析手法です。
また、クロス集計表からでも分析できます。対応分析や数量化III類と同様の手法です。類似する分析手法に主成分分析があります。
主な適用場面は、ポジショニングマップの作成や、クロス集計結果の視覚化が挙げられます。
■分析例:ターゲット世代と各社ブランドの関係は?
アルゴリズム
主成分とほぼ同等のアルゴリズム(ともに固有値問題)です。
左図のように2つの変数(x軸とy軸)で表されるデータがあります。
これらを左図の斜め線(合成変数)の座標に変換し、回転すると右図になります。
ここでは2変数を1変数に縮約しました。このようにして変数を合成します。
用語
・主成分(固有ベクトル):合成した変数
・主成分得点:データと主成分を掛けあわせたもの。
・固有値:主成分の情報の多少(主成分に対するデータのバラツキの大きさ)。もっとも大きい固有値に対応する主成分を第一主成分、その次に大きい固有値に対応する主成分を第2主成分と呼ぶ
・寄与率:各主成分がデータ全体に対しどれくらいの情報を持っているかは、その主成分が対応する固有値が固有値全体に締めている割合で説明できる。この割合を寄与率、その寄与率を累積したものを累積寄与率と呼ぶ
図の解釈
一番上のグラフはコレスポンデンス分析の分析結果を図示したものです。
・原点からの距離:嗜好性の強さ(長いほどバラツキがある、違いがある)。
・原点からの向きの向き:向きが近いほど項目間の関連性が強い。
・プロット(点):類似度の高い調査対象ほど近くにプロットされる。
- 2016年9月5日
ggplot2とは
ggplot2とは、R言語のグラフィック機能を拡張するパッケージです。本稿ではggplot2を利用した見栄えの良いグラフの作成について解説します。
ggplot2の特徴は、入力すべき情報やオプションが統一されているため、このパターンを覚えれば様々な種類のグラフを作る際にも同じ使い方ができることです。つまり、覚えることが少なくすみますので学習効率が高くなります。
この先、コードを実行しながら読み進める場合は、ggplot2パッケージを読み込みます。
library(ggplot2)
GGPLOT2のフロー
ggplot2の基本パターンは、入力データ、グラフの種類、体裁です。次に例示するコードをご参照ください。入力データはggplot()関数で指定し、グラフの種類はgeom_point()関数で指定しています。それ以降の箇所で細かな体裁を指定します。これらを「+」でつなぎ、1つのグラフを出力します。
### ...
- 2016年9月5日
類似度を距離で定量化し、その類似度をもとにグループ分けをします。
グループごとのデータを集計す ...
- 2016年9月5日
概要
同時に発生するデータに基づいて、その規則性を抽出します。相関ルール(アイテム間の組み合わせ規則)ごとの評価指標を抽出します。なお、説明を簡略化するためにアイテムの組み合わせと表現していますが、条件と結果の組み合わせを分析しているため、アイテムの他に性別や年齢などの条件を入れて分析することも可能です。例えば、20代男性(条件)がよく購入する商品(結果)を抽出することができます。
主な適用場面として、同時購入の規則性を利用した商品陳列の最適化や、セット販売、オプションサービスの提案があります。また、購入履歴やページ閲覧履歴から商品やコンテンツのレコメンデーションに使われます。
■分析例:同時購入を促しやすい商品の組み合わせは?
アルゴリズム
相関ルールの例
商品Aを買うと商品Bも買う: A ...
 なるべく情報を落とさずに少数の変数(次元)に要約する分析手法です。 複数項目のデータを2次元の図で視覚化する場合によく使われます。また、調査項目ごとの指向性の強さや関連性を定量化・視覚化することにも使われます。 類似する分析手法にコレスポンデンス分析があります。 属性などのカテゴリカルデータを含むデータを分析する際は、コレスポンデンス分析を使用します。 主な適用場面は、顧客の嗜好性や行動に基づくセグメンテーション、ポジショニングマップの作成が挙げられます。 ■分析例:どのようなセグメントに分けることができるか? アルゴリズム 左図のように2つの変数(x軸とy軸)で表されるデータがあります。これらを左図の斜め線(合成変数)の座標に変換し、回転すると右図になります。ここでは2変数を1変数に縮約しました。このようにして変数を合成します。 用語 ・主成分(固有ベクトル):合成した変数 ・主成分得点:データと主成分を掛けあわせたもの。 ・固有値:主成分の情報の多少(主成分に対するデータのバラツキの大きさ)。もっとも大きい固有値に対応する主成分を第一主成分、その次に大きい固有値に対応する主成分を第2主成分と呼ぶ。 ・寄与率:各主成分がデータ全体に対しどれくらいの情報を持っているかは、その主成分が対応する固有値が固有値全体に締めている割合で説明できる。この割合を寄与率、その寄与率を累積したものを累積寄与率と呼ぶ 図の解釈 一番上のグラフは主成分分析の分析結果を図示したものです。 ・矢印の長さ:嗜好性の強さ(長いほどバラツキがある、違いがある)。 ・矢印の向き:向きが近いほど項目間の関連性が強い。 ・プロット(点):類似度の高い調査対象ほど近くにプロットされる。
なるべく情報を落とさずに少数の変数(次元)に要約する分析手法です。 複数項目のデータを2次元の図で視覚化する場合によく使われます。また、調査項目ごとの指向性の強さや関連性を定量化・視覚化することにも使われます。 類似する分析手法にコレスポンデンス分析があります。 属性などのカテゴリカルデータを含むデータを分析する際は、コレスポンデンス分析を使用します。 主な適用場面は、顧客の嗜好性や行動に基づくセグメンテーション、ポジショニングマップの作成が挙げられます。 ■分析例:どのようなセグメントに分けることができるか? アルゴリズム 左図のように2つの変数(x軸とy軸)で表されるデータがあります。これらを左図の斜め線(合成変数)の座標に変換し、回転すると右図になります。ここでは2変数を1変数に縮約しました。このようにして変数を合成します。 用語 ・主成分(固有ベクトル):合成した変数 ・主成分得点:データと主成分を掛けあわせたもの。 ・固有値:主成分の情報の多少(主成分に対するデータのバラツキの大きさ)。もっとも大きい固有値に対応する主成分を第一主成分、その次に大きい固有値に対応する主成分を第2主成分と呼ぶ。 ・寄与率:各主成分がデータ全体に対しどれくらいの情報を持っているかは、その主成分が対応する固有値が固有値全体に締めている割合で説明できる。この割合を寄与率、その寄与率を累積したものを累積寄与率と呼ぶ 図の解釈 一番上のグラフは主成分分析の分析結果を図示したものです。 ・矢印の長さ:嗜好性の強さ(長いほどバラツキがある、違いがある)。 ・矢印の向き:向きが近いほど項目間の関連性が強い。 ・プロット(点):類似度の高い調査対象ほど近くにプロットされる。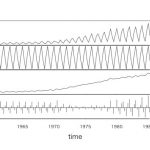 時系列データとは、対象の指標が時間に依存しているデータのことです。 例えば、株価や売上、体重など、前の観測値を基準に増減を調べるようなデータになります。 では、あなたが毎日サイコロを振って記録したとします。このサイコロの出た目の記録は時系列データでしょうか? 答えは「No」です。 前日にどんな目が出ようが、サイコロの目のそれぞれが出る確率は6分の1です(通常のサイコロでは)。つまり、前の観測値と次の観測値に関連性がないので、ここでの時系列データでないことになります。 解析時の計算や集計処理の方法が他のデータとは異なるところがあります。 時系列データを使って分析する目的は、変化のパターンを見つけることや、変化のきっかけ、変化の幅を把握することです。 大抵の場合、折れ線グラフを描画することでことたりるかと思います。
時系列データとは、対象の指標が時間に依存しているデータのことです。 例えば、株価や売上、体重など、前の観測値を基準に増減を調べるようなデータになります。 では、あなたが毎日サイコロを振って記録したとします。このサイコロの出た目の記録は時系列データでしょうか? 答えは「No」です。 前日にどんな目が出ようが、サイコロの目のそれぞれが出る確率は6分の1です(通常のサイコロでは)。つまり、前の観測値と次の観測値に関連性がないので、ここでの時系列データでないことになります。 解析時の計算や集計処理の方法が他のデータとは異なるところがあります。 時系列データを使って分析する目的は、変化のパターンを見つけることや、変化のきっかけ、変化の幅を把握することです。 大抵の場合、折れ線グラフを描画することでことたりるかと思います。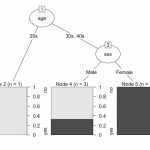 分析の基準になる変数が最も偏る切り口でグループ分けをし、以降、各グループに対しても同じ操作を繰り返します。 最も偏る切り口が分類の基準への影響が大きいと判断できます。 また、各グループに含まれる変数の割合により予測ルール(モデル)を構築します。予測したい対象がどのグループに属するかがわかれば、先の予測ルールにより予測ができます。 主な適用場面として、会員になりやすい顧客の特徴を調べる、離脱しやすいページを特定する等が挙げられます。 また、目的変数は質的データだけでなく、量的データでも同様に分析できます。目的変数が量的データの場合は、回帰木と呼ばれます。 さらに、この決定木の概念は機械学習を習得するための基礎になります。 ■分析例:どのような人が会員になりやすいか? アルゴリズム 目的変数が会員、非会員の例で決定木の構築方法(アルゴリズム)を考えてみます。 分割前のデータ(図では一番上の丸の中)に対して、ある説明変数で分割して分割後の目的変数の偏りぐわい(ジニ係数)を計算します。 目的変数に影響を大きく与えている切り口(説明変数)で分割した場合は、ジニ係数は小さくなり、分割した片方で会員の割合が大きくなり、もう片方で非会員の割合が大きくなります。 これをすべての説明変数で実行し、一番ジニ係数が小さくなる説明変数(分割基準)を見つけます。分割した後のグループに対しても同じことを実行していけば、最終的にツリー構造のルールが得られます。
分析の基準になる変数が最も偏る切り口でグループ分けをし、以降、各グループに対しても同じ操作を繰り返します。 最も偏る切り口が分類の基準への影響が大きいと判断できます。 また、各グループに含まれる変数の割合により予測ルール(モデル)を構築します。予測したい対象がどのグループに属するかがわかれば、先の予測ルールにより予測ができます。 主な適用場面として、会員になりやすい顧客の特徴を調べる、離脱しやすいページを特定する等が挙げられます。 また、目的変数は質的データだけでなく、量的データでも同様に分析できます。目的変数が量的データの場合は、回帰木と呼ばれます。 さらに、この決定木の概念は機械学習を習得するための基礎になります。 ■分析例:どのような人が会員になりやすいか? アルゴリズム 目的変数が会員、非会員の例で決定木の構築方法(アルゴリズム)を考えてみます。 分割前のデータ(図では一番上の丸の中)に対して、ある説明変数で分割して分割後の目的変数の偏りぐわい(ジニ係数)を計算します。 目的変数に影響を大きく与えている切り口(説明変数)で分割した場合は、ジニ係数は小さくなり、分割した片方で会員の割合が大きくなり、もう片方で非会員の割合が大きくなります。 これをすべての説明変数で実行し、一番ジニ係数が小さくなる説明変数(分割基準)を見つけます。分割した後のグループに対しても同じことを実行していけば、最終的にツリー構造のルールが得られます。 商品レビューや口コミ、問い合わせ、クレーム等顧客の声を分析するために、「テキストマイニング」といわれる手法があります。 テキストマイニングでは、文章などの定性的なデータを定量的なデータに変換し、様々な解析手法を適用します。 文章等の定性的なデータを人海戦術で処理していたものを、分析を用いて自働化・半自動化することで、業務効率向上による人件費の削減や、システム化が可能になります。 テキストマイニングで用いられる手法に「形態素解析」「ワードカウンティング」「共起分析」などがあります。 形態素解析は、機械が単語を認識するための手法で、文章を単語などに分けます。 ワードカウンティングでは、形態素解析で切り分けられた単語の各文章中における出現頻度を集計します。 アウトプットはクロス集計表をイメージしてください。この集計表では定量データに変換されているため、さまざまな解析手法を適用することができます。 共起分析では、単語同士のつながりを分析します。例えば、同じ文章中に出現しやすい単語をネットワークで表現します。 「R」に関連するTwitterを共起分析した例
商品レビューや口コミ、問い合わせ、クレーム等顧客の声を分析するために、「テキストマイニング」といわれる手法があります。 テキストマイニングでは、文章などの定性的なデータを定量的なデータに変換し、様々な解析手法を適用します。 文章等の定性的なデータを人海戦術で処理していたものを、分析を用いて自働化・半自動化することで、業務効率向上による人件費の削減や、システム化が可能になります。 テキストマイニングで用いられる手法に「形態素解析」「ワードカウンティング」「共起分析」などがあります。 形態素解析は、機械が単語を認識するための手法で、文章を単語などに分けます。 ワードカウンティングでは、形態素解析で切り分けられた単語の各文章中における出現頻度を集計します。 アウトプットはクロス集計表をイメージしてください。この集計表では定量データに変換されているため、さまざまな解析手法を適用することができます。 共起分析では、単語同士のつながりを分析します。例えば、同じ文章中に出現しやすい単語をネットワークで表現します。 「R」に関連するTwitterを共起分析した例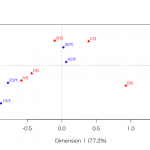 コレスポンデンス分析は、ポジショニングを直感的に理解できるマップを提供します。 実数だけでなく、カテゴリーデータも分析できるため、適用範囲が広い分析手法です。 また、クロス集計表からでも分析できます。対応分析や数量化III類と同様の手法です。類似する分析手法に主成分分析があります。 主な適用場面は、ポジショニングマップの作成や、クロス集計結果の視覚化が挙げられます。 ■分析例:ターゲット世代と各社ブランドの関係は? アルゴリズム 主成分とほぼ同等のアルゴリズム(ともに固有値問題)です。 左図のように2つの変数(x軸とy軸)で表されるデータがあります。 これらを左図の斜め線(合成変数)の座標に変換し、回転すると右図になります。 ここでは2変数を1変数に縮約しました。このようにして変数を合成します。 用語 ・主成分(固有ベクトル):合成した変数 ・主成分得点:データと主成分を掛けあわせたもの。 ・固有値:主成分の情報の多少(主成分に対するデータのバラツキの大きさ)。もっとも大きい固有値に対応する主成分を第一主成分、その次に大きい固有値に対応する主成分を第2主成分と呼ぶ ・寄与率:各主成分がデータ全体に対しどれくらいの情報を持っているかは、その主成分が対応する固有値が固有値全体に締めている割合で説明できる。この割合を寄与率、その寄与率を累積したものを累積寄与率と呼ぶ 図の解釈 一番上のグラフはコレスポンデンス分析の分析結果を図示したものです。 ・原点からの距離:嗜好性の強さ(長いほどバラツキがある、違いがある)。 ・原点からの向きの向き:向きが近いほど項目間の関連性が強い。 ・プロット(点):類似度の高い調査対象ほど近くにプロットされる。
コレスポンデンス分析は、ポジショニングを直感的に理解できるマップを提供します。 実数だけでなく、カテゴリーデータも分析できるため、適用範囲が広い分析手法です。 また、クロス集計表からでも分析できます。対応分析や数量化III類と同様の手法です。類似する分析手法に主成分分析があります。 主な適用場面は、ポジショニングマップの作成や、クロス集計結果の視覚化が挙げられます。 ■分析例:ターゲット世代と各社ブランドの関係は? アルゴリズム 主成分とほぼ同等のアルゴリズム(ともに固有値問題)です。 左図のように2つの変数(x軸とy軸)で表されるデータがあります。 これらを左図の斜め線(合成変数)の座標に変換し、回転すると右図になります。 ここでは2変数を1変数に縮約しました。このようにして変数を合成します。 用語 ・主成分(固有ベクトル):合成した変数 ・主成分得点:データと主成分を掛けあわせたもの。 ・固有値:主成分の情報の多少(主成分に対するデータのバラツキの大きさ)。もっとも大きい固有値に対応する主成分を第一主成分、その次に大きい固有値に対応する主成分を第2主成分と呼ぶ ・寄与率:各主成分がデータ全体に対しどれくらいの情報を持っているかは、その主成分が対応する固有値が固有値全体に締めている割合で説明できる。この割合を寄与率、その寄与率を累積したものを累積寄与率と呼ぶ 図の解釈 一番上のグラフはコレスポンデンス分析の分析結果を図示したものです。 ・原点からの距離:嗜好性の強さ(長いほどバラツキがある、違いがある)。 ・原点からの向きの向き:向きが近いほど項目間の関連性が強い。 ・プロット(点):類似度の高い調査対象ほど近くにプロットされる。 ggplot2とは ggplot2とは、R言語のグラフィック機能を拡張するパッケージです。本稿ではggplot2を利用した見栄えの良いグラフの作成について解説します。 ggplot2の特徴は、入力すべき情報やオプションが統一されているため、このパターンを覚えれば様々な種類のグラフを作る際にも同じ使い方ができることです。つまり、覚えることが少なくすみますので学習効率が高くなります。 この先、コードを実行しながら読み進める場合は、ggplot2パッケージを読み込みます。 library(ggplot2) GGPLOT2のフロー ggplot2の基本パターンは、入力データ、グラフの種類、体裁です。次に例示するコードをご参照ください。入力データはggplot()関数で指定し、グラフの種類はgeom_point()関数で指定しています。それ以降の箇所で細かな体裁を指定します。これらを「+」でつなぎ、1つのグラフを出力します。 ### ...
ggplot2とは ggplot2とは、R言語のグラフィック機能を拡張するパッケージです。本稿ではggplot2を利用した見栄えの良いグラフの作成について解説します。 ggplot2の特徴は、入力すべき情報やオプションが統一されているため、このパターンを覚えれば様々な種類のグラフを作る際にも同じ使い方ができることです。つまり、覚えることが少なくすみますので学習効率が高くなります。 この先、コードを実行しながら読み進める場合は、ggplot2パッケージを読み込みます。 library(ggplot2) GGPLOT2のフロー ggplot2の基本パターンは、入力データ、グラフの種類、体裁です。次に例示するコードをご参照ください。入力データはggplot()関数で指定し、グラフの種類はgeom_point()関数で指定しています。それ以降の箇所で細かな体裁を指定します。これらを「+」でつなぎ、1つのグラフを出力します。 ### ...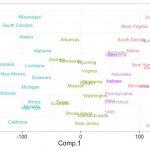 類似度を距離で定量化し、その類似度をもとにグループ分けをします。 グループごとのデータを集計す ...
類似度を距離で定量化し、その類似度をもとにグループ分けをします。 グループごとのデータを集計す ...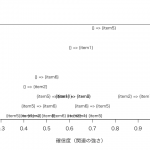 概要 同時に発生するデータに基づいて、その規則性を抽出します。相関ルール(アイテム間の組み合わせ規則)ごとの評価指標を抽出します。なお、説明を簡略化するためにアイテムの組み合わせと表現していますが、条件と結果の組み合わせを分析しているため、アイテムの他に性別や年齢などの条件を入れて分析することも可能です。例えば、20代男性(条件)がよく購入する商品(結果)を抽出することができます。 主な適用場面として、同時購入の規則性を利用した商品陳列の最適化や、セット販売、オプションサービスの提案があります。また、購入履歴やページ閲覧履歴から商品やコンテンツのレコメンデーションに使われます。 ■分析例:同時購入を促しやすい商品の組み合わせは? アルゴリズム 相関ルールの例 商品Aを買うと商品Bも買う: A ...
概要 同時に発生するデータに基づいて、その規則性を抽出します。相関ルール(アイテム間の組み合わせ規則)ごとの評価指標を抽出します。なお、説明を簡略化するためにアイテムの組み合わせと表現していますが、条件と結果の組み合わせを分析しているため、アイテムの他に性別や年齢などの条件を入れて分析することも可能です。例えば、20代男性(条件)がよく購入する商品(結果)を抽出することができます。 主な適用場面として、同時購入の規則性を利用した商品陳列の最適化や、セット販売、オプションサービスの提案があります。また、購入履歴やページ閲覧履歴から商品やコンテンツのレコメンデーションに使われます。 ■分析例:同時購入を促しやすい商品の組み合わせは? アルゴリズム 相関ルールの例 商品Aを買うと商品Bも買う: A ...