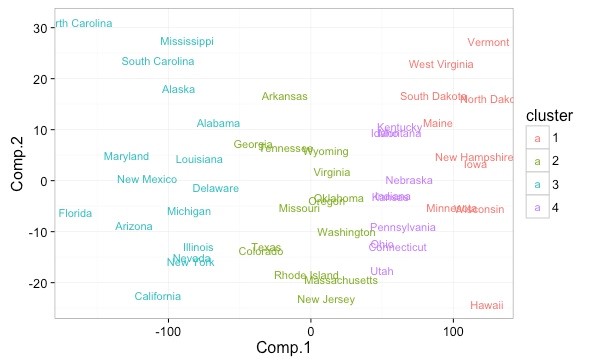
クラスター分析:似ている物同士をグルーピング
類似度を距離で定量化し、その類似度をもとにグループ分けをします。
グループごとのデータを集計す ることで、グループの典型的な振る舞いを推定することができます。
また、視覚化するために、主成分 分析やコレスポンデンス分析と併用されることが多いです。
主な適用場面は、セグメンテーション(消費者や競合、商品の分類など)が挙げられます。
クラスター分析は、階層的クラスター分析と非階層的スラスター分析に大別されます。
階層的クラスター分析とは、個体間の類似度に基づいて、似ている個体から順次集めてクラスターを作っていく方法で、樹形図で示すことができます。
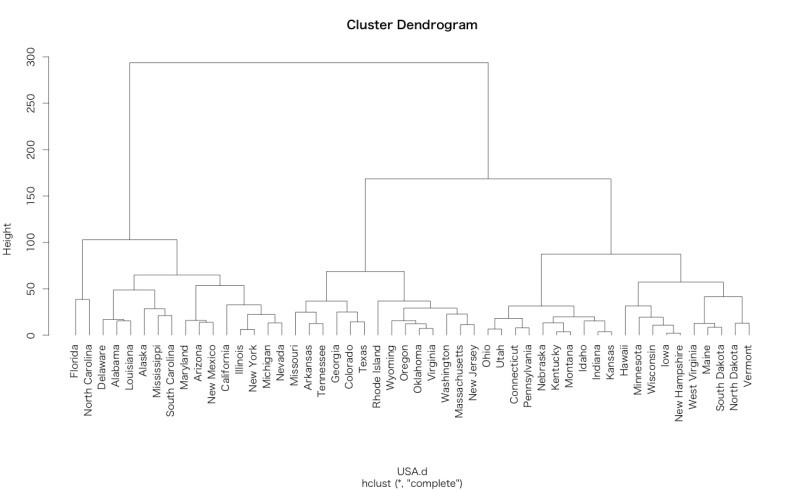
非階層的クラスター分析は、階層的クラスターに比べ計算量が少ないため、大規模データに向いています。
代表的な方法としてk-means法があります。k-means法の流れは、まず任意の個数のクラスターの中心を適当に与えます。
すべてのデータとクラスターの中心との距離を求め、最も近いクラスターに分類します。
新たに形成されたクラスターの中心を求めます。再びデータと新たなクラスターの中心との距離から分類し、クラスターの中心を求めます。
クラスターの中心の位置が変化しなくなるまで繰り返します。