Step.5 課題解決に必要な情報の取得方法を検討する
解説
前のステップで策定した課題解決策、データ分析のソリューションに対して必要な情報を特定します。このステップでは、欲しい情報から逆算して、解析方法(データマイニングタスク)やそのインプットとして必要なデータを洗い出し、整理します。
課題解決に必要な情報を特定する
欲しいデータを洗い出すポイントは、必要な情報から逆算することです。具体的には、課題解決に対し必要な情報、それを得るために必要なデータマイニングタスク、そのために必要なデータの順で整理します。次図の左から埋めていくイメージです。ここで整理した図は、分析スクリプトのフローチャートとしても活用できます。
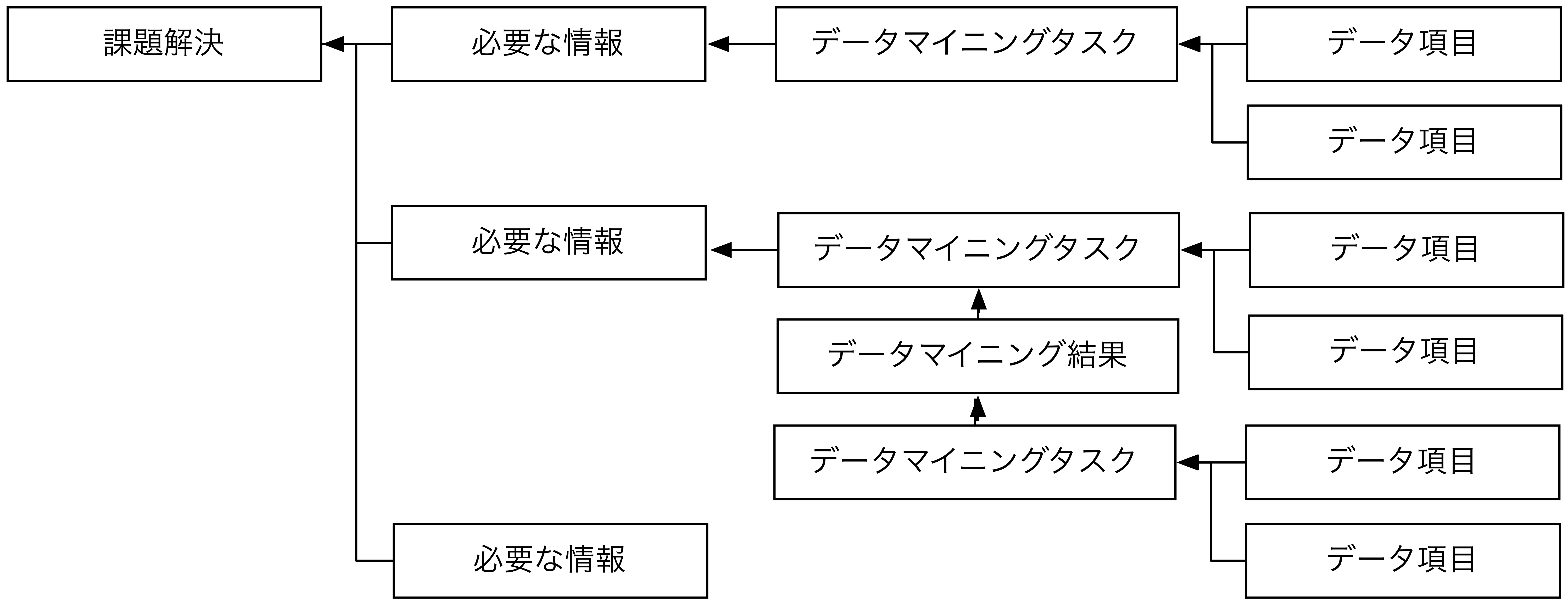
データの具体的な内容や取得方法は業種や企業により異なります。そのため、業務担当者へのヒアリングやグループワークを通じて検討する必要があります。この際に、事前に分析結果を想定します。これにより、データ収集時や実際の分析結果から、想定していなかった(気づいていなかった)情報を発見することが容易になります。
ケーススタディ
前のステップで、データ分析のソリューションを「リピート率に影響を与えている要因とその程度を明らかにする」と設定しました。これは「リピートするか or しないか」を分類する問題として分析することになります。
具体的には分析手法として、決定木分析を用いることにします。決定木分析は、分類の基準になる変数(「リピートするか or しないか」)が最も偏る切り口(リピートに影響を与える要因)でグループ分けをし、以降、各グループに対して同じ操作を繰り返すことで、最もきれいに分解できる軸を見つける手法です。通常、エクセルなどでクロス集計をしていくこともあるかと思いますが、項目の組み合わせ数を考えると、とても人間が網羅できる量ではありません。ですので、必然的に決定木などの分析手法が必要となってきます。
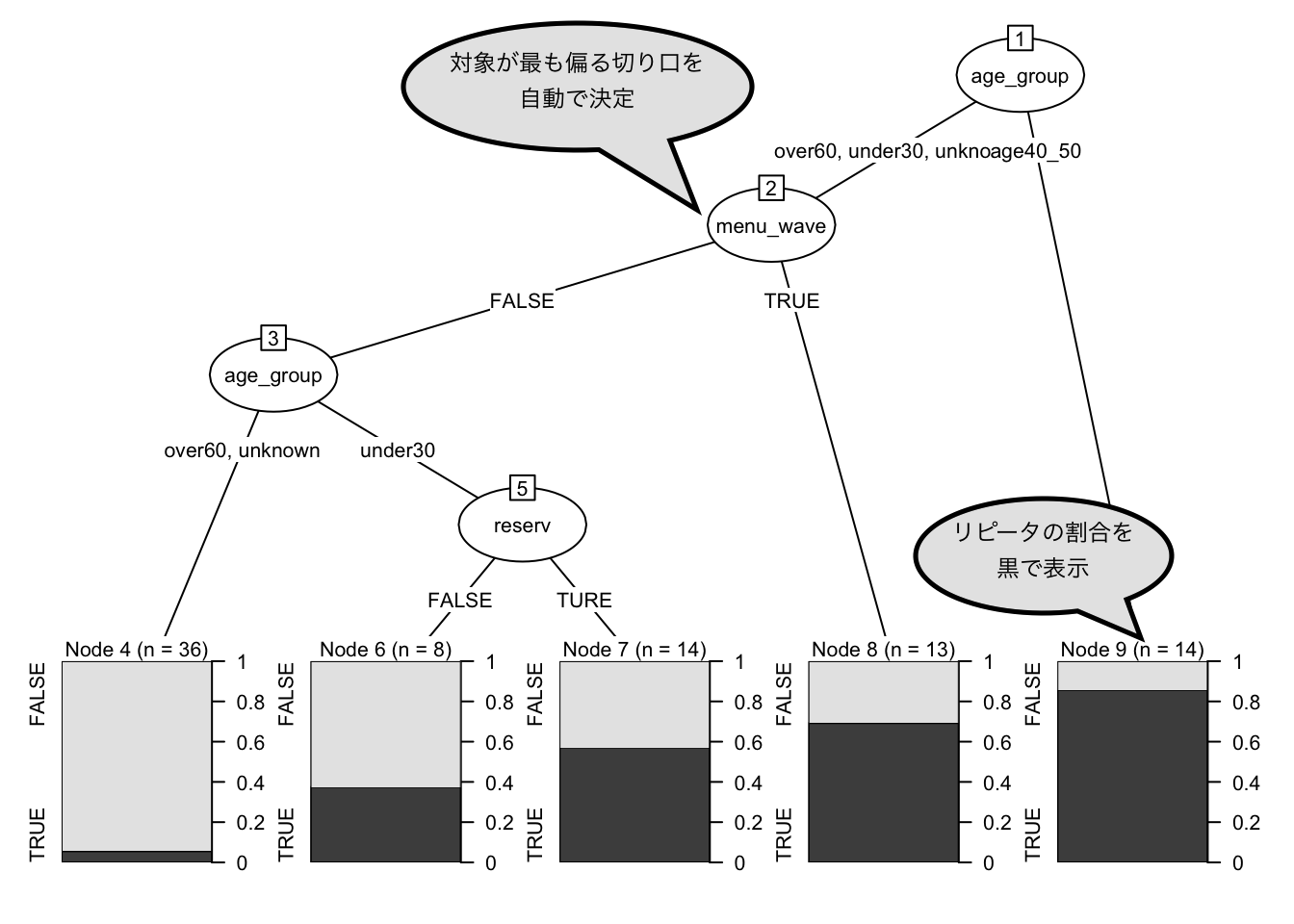
この分析に必要な情報(データ)として次のようなものが考えられます。
- 予測対象:「リピートしたか or していないか」
- リピートへ影響を与えているだろう要因:顧客情報(性別、年齢層)、利用メニュー、担当スタイリスト、予約タイミング
また、モデル作成には使いませんがリピート率の推移を見るために「新規顧客の来店日」も必要になります。

ワーク:決定木分析は、他にどんな場面で使えそうですか?思いつく限り書き出してみてください。 (例)webサイトでどのようなコンテンツを読んだ人がコンバージョン(資料請求)をしたか。