Case10. 顧客価値を予測する
- データの理解
与えられたデータを見ていき、現状把握や、顧客価値(outcome)に影響を及ぼす要因を探っていきます。
kaggle data description (データの説明)
- 人物ファイルと行動ファイルの2つのテーブルがあり、これらはperson_idで結合できる
- ビジネス価値は各行動に対して定義されている(行動ファイルのoutcomeカラム)
人物ファイル
- 各行に一意の人物を表し、その属性情報とその人が行った行動情報が含まれる
行動ファイル
- 各行に特定の人物が行った行動とそのビジネス価値が含まれる
- 行動は幾つかのカテゴリに分類される
- type1の行動は9つの特徴と関連している
- type2-7の行動は1つの特徴と関連している
ここからは、実際にデータを整理していきます(コード部分に興味のない人はコードは読み飛ばして頂いて結構です)。
参考:
https://www.kaggle.com/emeller/first-exploratory
準備
# ライブラリの読み込み
library(data.table)
library(dplyr)
library(ggplot2)
library(stringr)
# データの読み込み
train <- fread("./data/case10_act_train.csv", showProgress = FALSE, data.table = FALSE)
people <- fread("./data/case10_people.csv", showProgress = FALSE, data.table = FALSE)
### 前処理
# char_2と同じなので除外
people$char_1 <- NULL
# date in year, month and day
people$year <- as.integer(substr(people$date, 1, 4))
people$month <- as.integer(substr(people$date, 6, 7))
people$day <- as.integer(substr(people$date, 9, 10))
people <- select(people, -date)
train$year <- as.integer(substr(train$date, 1, 4))
train$month <- as.integer(substr(train$date, 6, 7))
train$day <- as.integer(substr(train$date, 9, 10))
train <- select(train, -date)
# 論理型をダミー変数に変換
p_logi <- names(people)[which(sapply(people, is.logical))]
for (col in p_logi) set(people, j = col, value = as.numeric(people[[col]]))
# trainとpeopleに同じカラム名があるのでカラム名を変更
names(people)[2:ncol(people)] <- paste0('people_', names(people)[2:ncol(people)])
## テーブルの結合
data <- left_join(train, people, by = "people_id")
# 0と1しかないのでファクター型に変換
data$outcome <- as.factor(data$outcome)データ概要
dim(data)## [1] 2197291 58人物ファイルと行動ファイル結合後、2197291件、58項目
length(unique(data$people_id))## [1] 151295151295人分のデータ
行動数の分布
group_by(data, people_id, outcome) %>%
summarise(active_count = n()) %>%
filter(active_count < 100) %>%
ggplot(aes(x = active_count, fill = outcome)) +
geom_histogram(position = "identity", alpha = 0.6)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.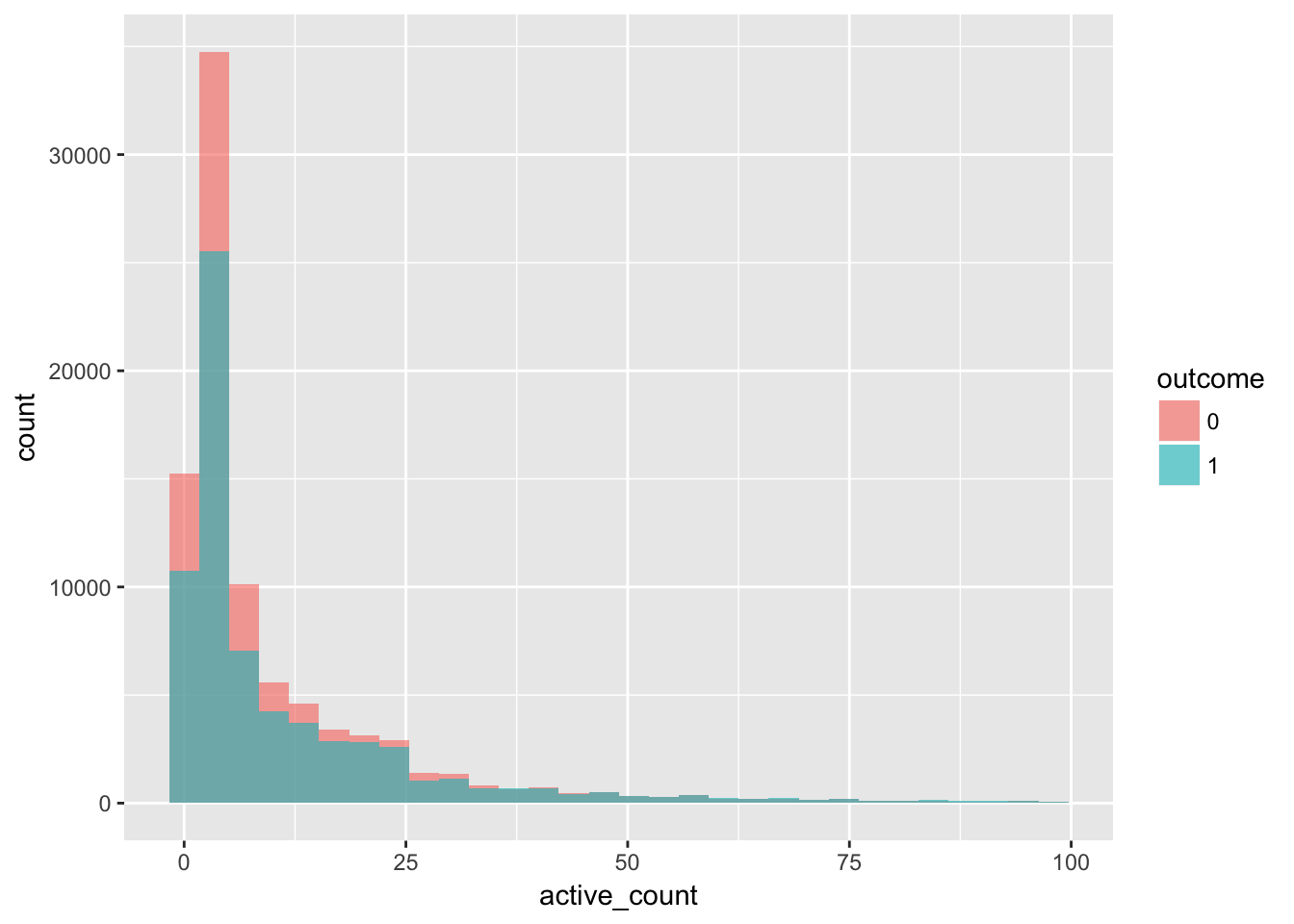
行動カテゴリー(activity_category)の分布
group_by(data, activity_category, outcome) %>%
summarise(count = n()) %>%
ggplot(aes(x = activity_category, y = count, fill = outcome)) +
geom_bar(stat = "identity")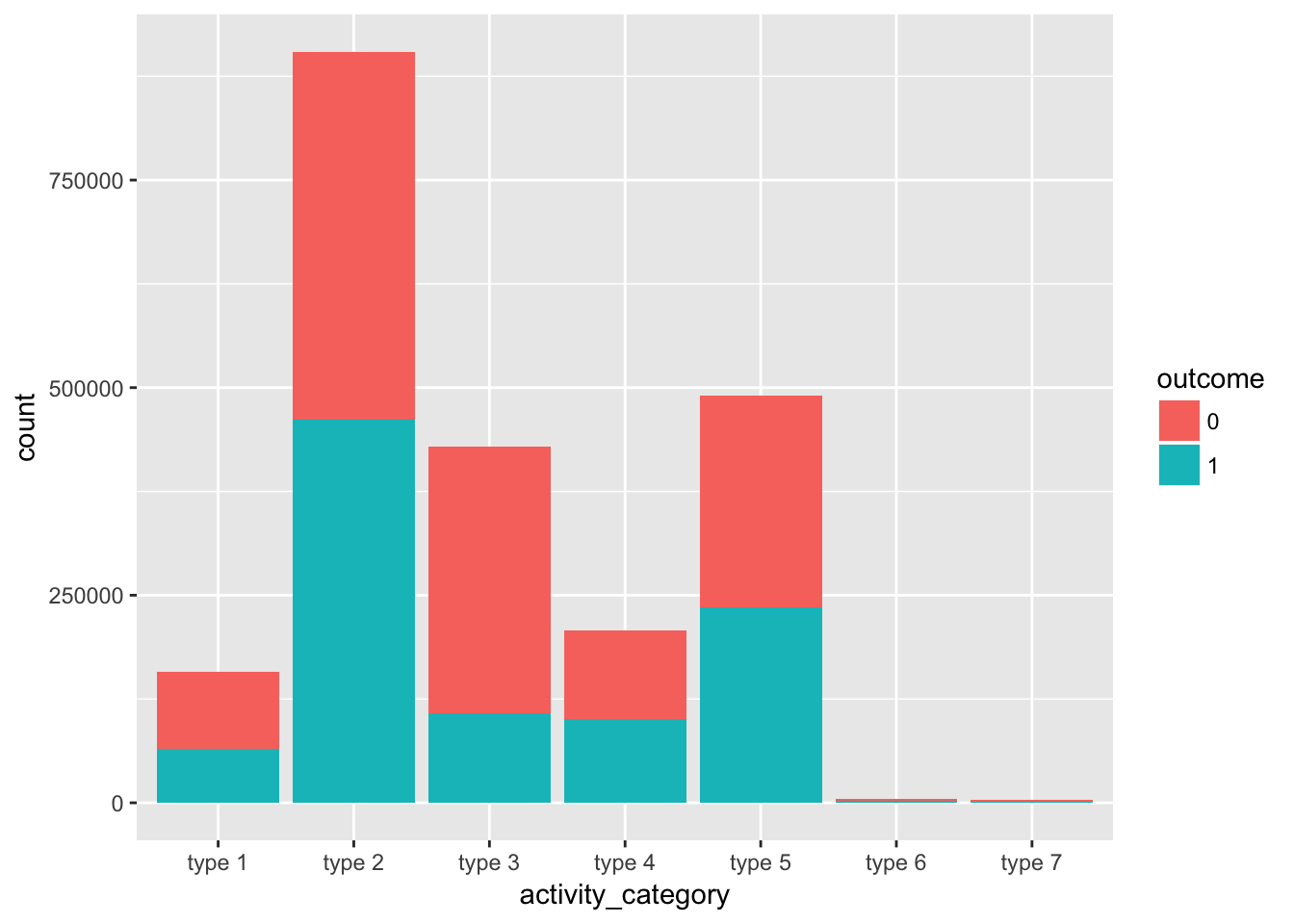
まとめ
- 人物ファイルと行動ファイル結合後、2197291件、58項目
- 151295人分のデータ
- 一人当たり行動数のボリュームゾーンは5から10で、outcomeとの関連は薄い
- 行動カテゴリーは、type2とtype5が多く、type3でoutcomeにわずかに偏りがある