Case6. 顧客の満足、不満足を予測する
- モデリング
実際にランダムフォレストを使って、顧客満足予測モデルを作成していきます。
フロー
- データセットの作成
- モデル作成用、検証用にデータセットを分離
- モデル作成用のデータセットでモデリング
- モデルでの予測値(検証用データの各要因をモデルに適用した結果)と検証用データの比較
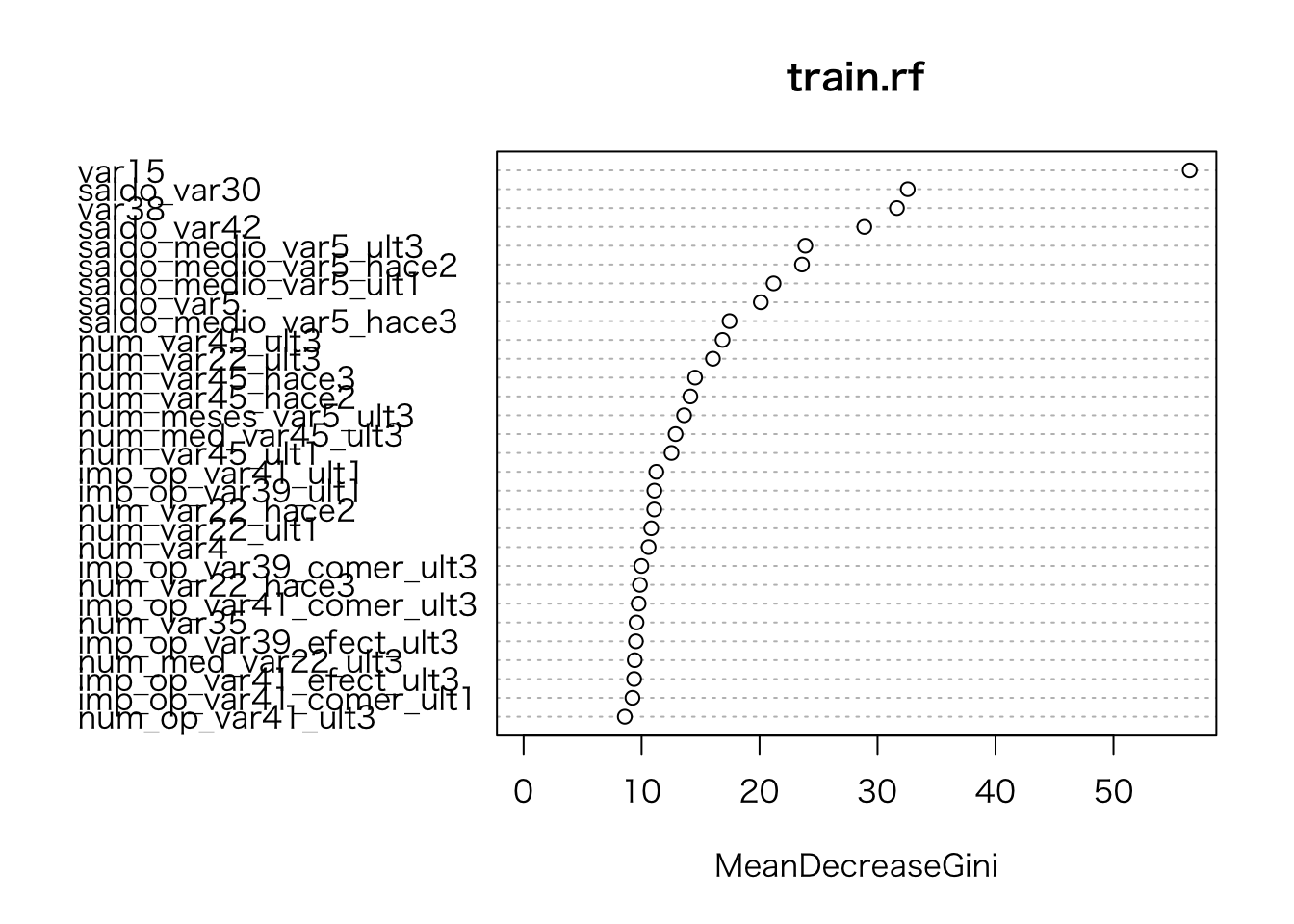
- モデル内容
https://www.kaggle.com/vatsal2020/to-the-top-v33
# ライブラリの読み込み
#library(data.table)
library(dplyr)
library(ggplot2)
library(randomForest)
# データの読み込み
#data <- fread("./data/case06_train.csv", showProgress = FALSE, data.table = FALSE)
data <- read.csv("./data/case06_train.csv")データセットの作成
# 欠損値の処理
data[is.na(data)] <- -1
# IDは除外
data <- select(data, -ID)
# データ型の変更
data$TARGET <- as.factor(data$TARGET)
# すべてのデータを使うと時間がかかるので調整
#model.dat <- data[1:10000,]
model.dat <- dataデータセットの分離
# トレーニング用にサンプルをランダムに抽出
train.index <- sort(sample(1:nrow(model.dat), size = 50000))
#モデリング用と検証用にデータセットを分離
train <- model.dat[train.index,]
test <- model.dat[-train.index,]モデリング
ランダムフォレストでモデリング
# この処理は時間がかかります
# チューニング
feature.names <- names(model.dat)[1:ncol(model.dat)-1]
train.tune <- tuneRF(train[,feature.names], train$TARGET, doBest = T)## mtry = 19 OOB error = 3.93%
## Searching left ...
## mtry = 10 OOB error = 3.92%
## 0.0005094244 0.05
## Searching right ...
## mtry = 38 OOB error = 3.94%
## -0.00356597 0.05
# モデリング
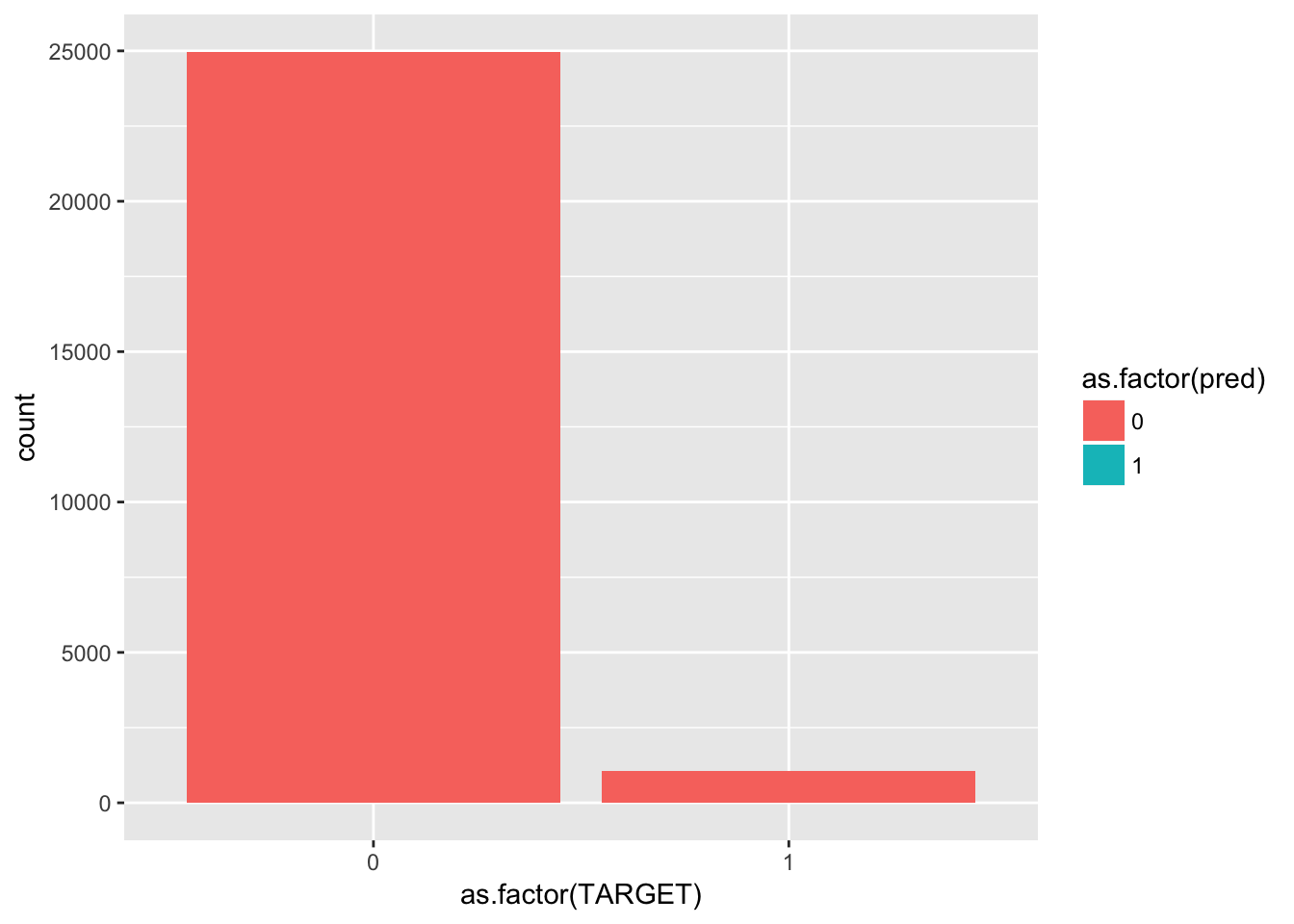
train.rf <- randomForest(TARGET ~., data = train, mtry = train.tune$mtry )モデルの評価(検証用データと予測値の比較)
# 検証用データにモデルを適用
test$pred <- predict(train.rf, test)
group_by(test,pred,TARGET) %>%
summarise(count = n()) %>%
ggplot(aes(x = as.factor(TARGET), y = count, fill = as.factor(pred))) +
geom_bar(stat = "identity")