Case6. 顧客の満足、不満足を予測する
- データの理解
与えられたデータについて見ていき、現状把握や、顧客満足に影響を及ぼす要因を探っていきます。
kaggle data description (データの説明)
- 多数の数値変数を含む匿名化されたデータセット
- “TARGET”は 満足していない顧客の場合は1、満足した顧客の場合は0
- その他の項目についての説明なし
ここからは、実際にデータを整理していきます(コード部分に興味のない人はコードは読み飛ばして頂いて結構です)。
参考:https://www.kaggle.com/cast42/exploring-features
準備
# ライブラリの読み込み
library(data.table)
library(dplyr)
library(ggplot2)
# データの読み込み
train <- fread("./data/case06_train.csv", showProgress = FALSE, data.table = FALSE)データ概要
dim(train)## [1] 76020 371371項目、7602件のデータセット
TARGET(満足、不満足)
group_by(train, TARGET) %>%
summarise(count = n()) %>%
ggplot(aes(x = as.factor(TARGET), y = count)) +
geom_bar(stat = "identity")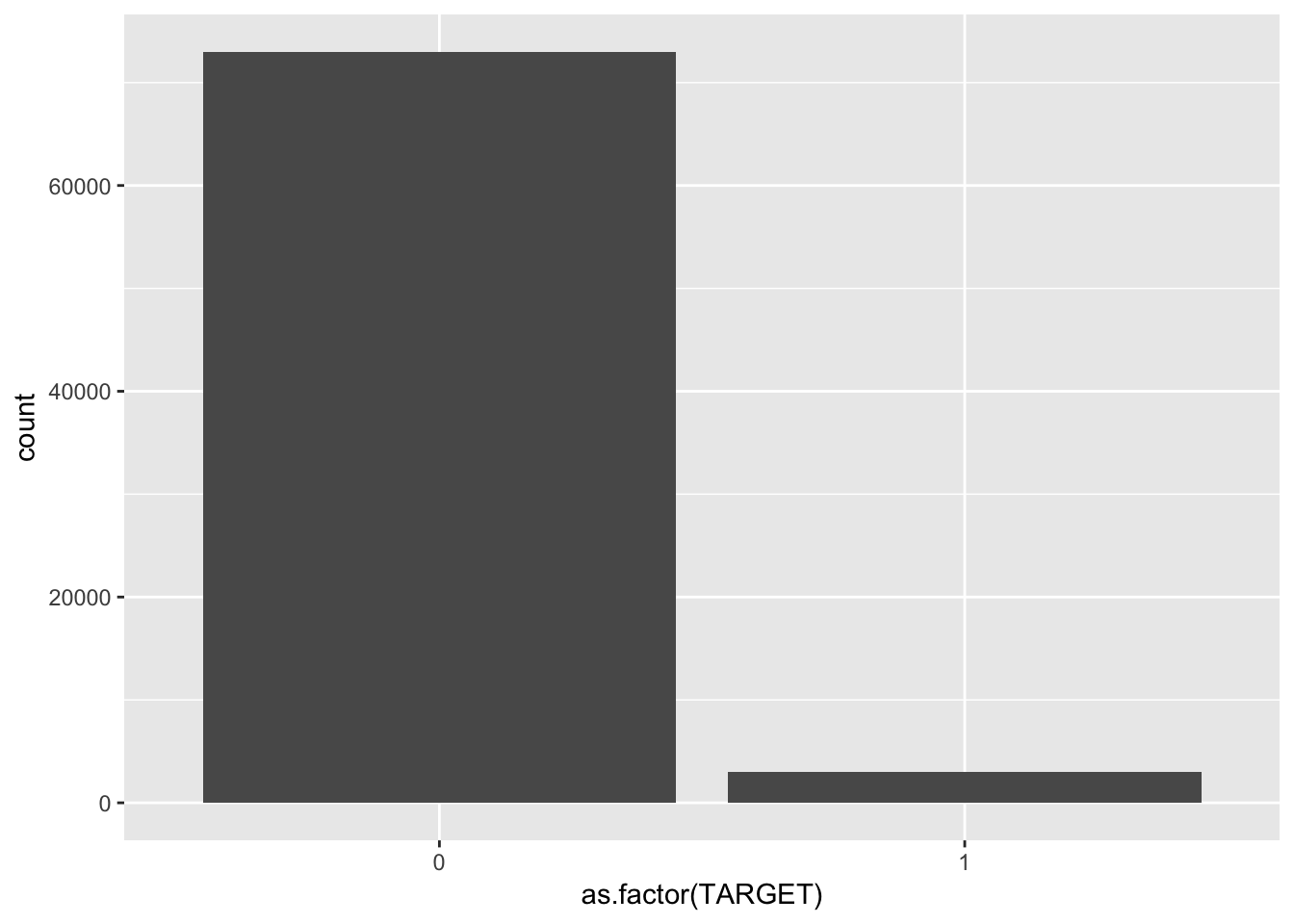
TARGETが1(満足していない顧客)は約4%
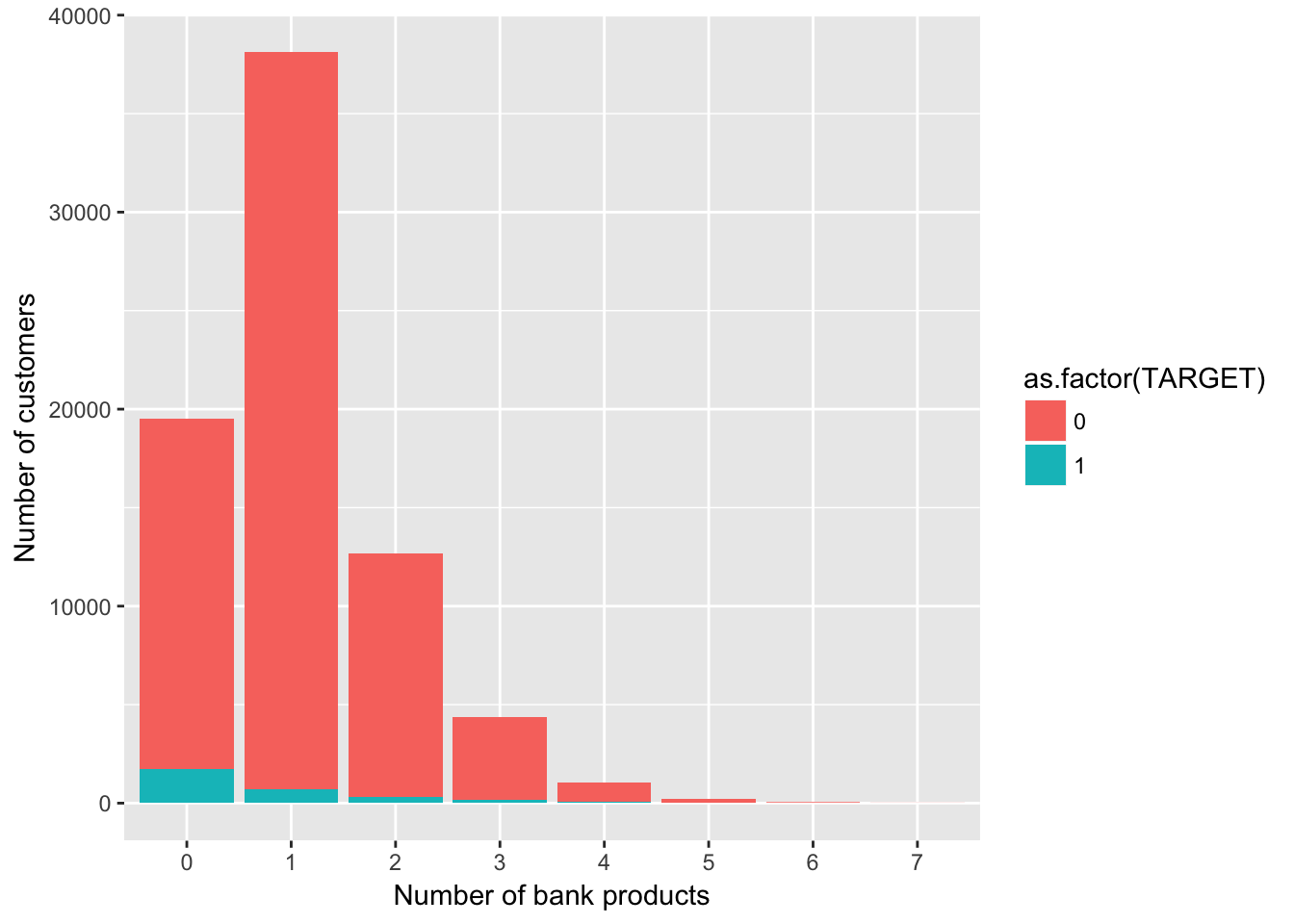
利用している商品数
次のポストによると「num_var4」は利用商品数
https://www.kaggle.com/cast42/santander-customer-satisfaction/exploring-features/comments#115223
group_by(train, num_var4) %>%
summarise(count = n()) %>%
ggplot(aes(x = as.factor(num_var4), y = count)) +
geom_bar(stat = "identity") +
labs(x ="Number of bank products", y ="Number of customers")
group_by(train, num_var4, TARGET) %>%
summarise(count = n()) %>%
ggplot(aes(x = as.factor(num_var4), y = count, fill = as.factor(TARGET))) +
geom_bar(stat = "identity") +
labs(x ="Number of bank products", y ="Number of customers")