Case4. ユーザーの旅行先を予測する
- モデリング
実際にランダムフォレストを使って、旅行先予測モデルを作成していきます。 コンペでは、他にwebサイトのログなどの情報もありますが、ここではユーザ情報のみを使ってモデルを作成します。
# ライブラリの読み込み
library(data.table)
library(dplyr)
library(stringr)
library(ggplot2)
library(randomForest)
# データの読み込み
data <- fread("./data/case04_train_users_2.csv", showProgress = FALSE, data.table = FALSE)データセットの作成
# IDの削除
data <- select(data, -id)
# 欠損値の処理
data[is.na(data)] <- -1
# date_account_created in year, month and day
data$dac_year <- as.integer(substr(data$date_account_created, 1, 4))
data$dac_month <- as.integer(substr(data$date_account_created, 6, 7))
data$dac_day <- as.integer(substr(data$date_account_created, 9, 10))
data <- select(data, -date_account_created)
# timestamp_first_active in year, month and day
data$tfa_year <- as.integer(substr(data$timestamp_first_active, 1, 4))
data$tfa_month <- as.integer(substr(data$timestamp_first_active, 5, 6))
data$tfa_day <- as.integer(substr(data$timestamp_first_active, 7, 8))
data <- select(data, -timestamp_first_active)
# clean age
data[data$age > 100, "age"] <- -1
# dummyVars
label <- data$country_destination
for (f in names(data)) {
if (class(data[[f]])=="character") {
levels <- unique(data[[f]])
data[[f]] <- as.integer(factor(data[[f]], levels=levels))
}
}
data$country_destination <- as.factor(label)
# 予約してはじめて分かる情報なので除外
data <- select(data, -date_first_booking) データセットの分離
# 2014年以降初めてアクションを起こしたユーザを新規ユーザ(検証用)とする
train <- filter(data, tfa_year < 2014)
test <- filter(data, tfa_year >= 2014) モデリング
ランダムフォレストでモデリング
# この処理は時間がかかります
# チューニング
train.tune <- tuneRF(train[, -12], train[, 12], doBest = T)## mtry = 4 OOB error = 39.97%
## Searching left ...
## mtry = 2 OOB error = 38.61%
## 0.03407161 0.05
## Searching right ...
## mtry = 8 OOB error = 42.66%
## -0.0673946 0.05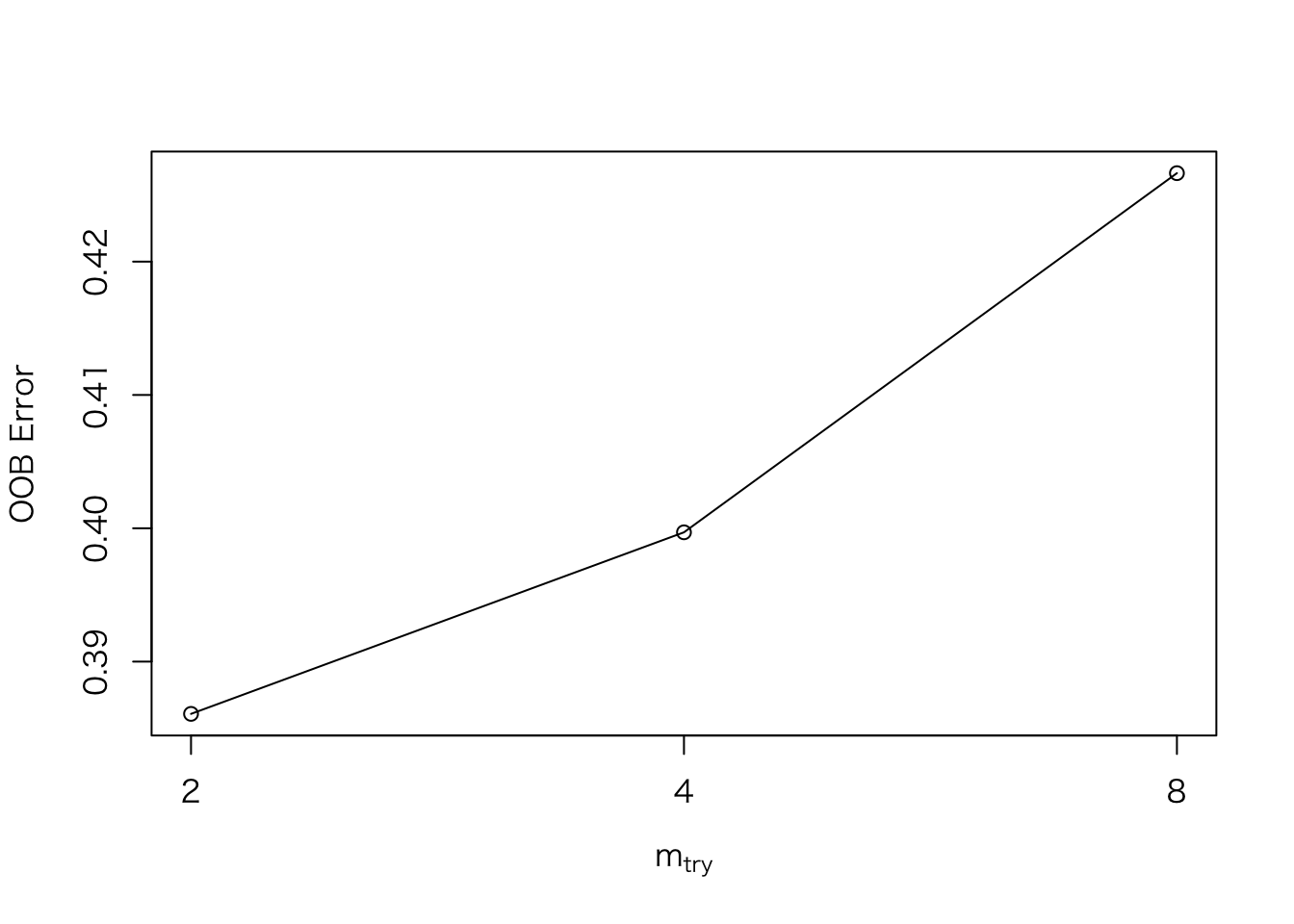
# モデリング
train.rf <- randomForest(country_destination ~., data = train, mtry = train.tune$mtry)モデルの評価(検証用データと予測値の比較)
# 検証用データにモデルを適用
test$pred <- predict(train.rf, test)
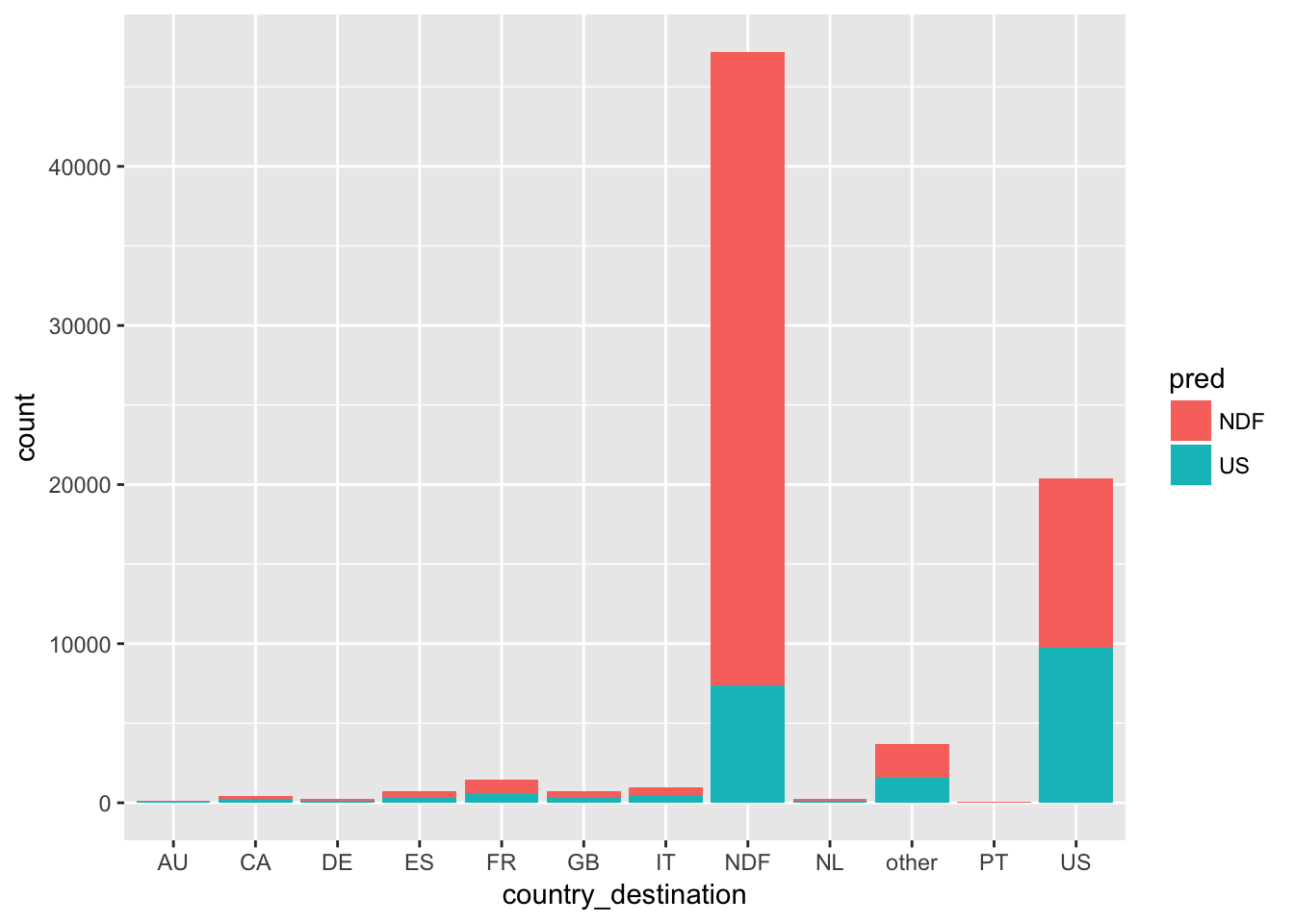
group_by(test, country_destination, pred) %>%
summarise(count = n()) %>%
ggplot(aes(x = country_destination, y = count, fill = pred)) +
geom_bar(stat = "identity")