Step.7 収集した情報を整理、分析する
解説
このステップでは、収集したデータを整理、分析し、目標との関連性やその制限(欠損値や情報源の偏り、データ量)を把握します。 そのために、できる限りデータを視覚化していきます。その際、次のように目的に応じてグラフを作成します。
- データの推移をみる (折れ線グラフ)
- データの分布をみる (ヒストグラム)
- データの分布をみる (箱ひげ図)
- 大きさの比をみる (棒グラフ)
- 内訳をみる (帯グラフ)
- データの関係をみる (散布図)
- データの関係をみる (ヒートマップ)
ここでのポイントは
- ターゲット(KPIや予測対象)の値は、推移や分布で必ずグラフにすること
- データ量、外れ値、欠損値、入力ミスなどを確認すること
予測モデル作成を含むプロジェクトの場合は、予測対象とその他のデータ項目との関連性をざっくりと分析します。単純な一対一の相関などであればこの段階であたりがつきますが、複数の条件を加味する場合は、一旦予測モデルを作成しそこから逆算するなどのテクニックを使った方が効率的です。
ケーススタディ
ワーク:どのようなグラフを作成すればよいでしょうか?データ項目(グラフの種類)をあげてください。
収集したデータ項目:リピートの発生、 顧客情報(性別、年齢層)、利用メニュー、担当スタイリスト、予約タイミング、新規来店日
では、いくつか見ていきましょう。
新規顧客数とそのリピータ数の月ごとの推移

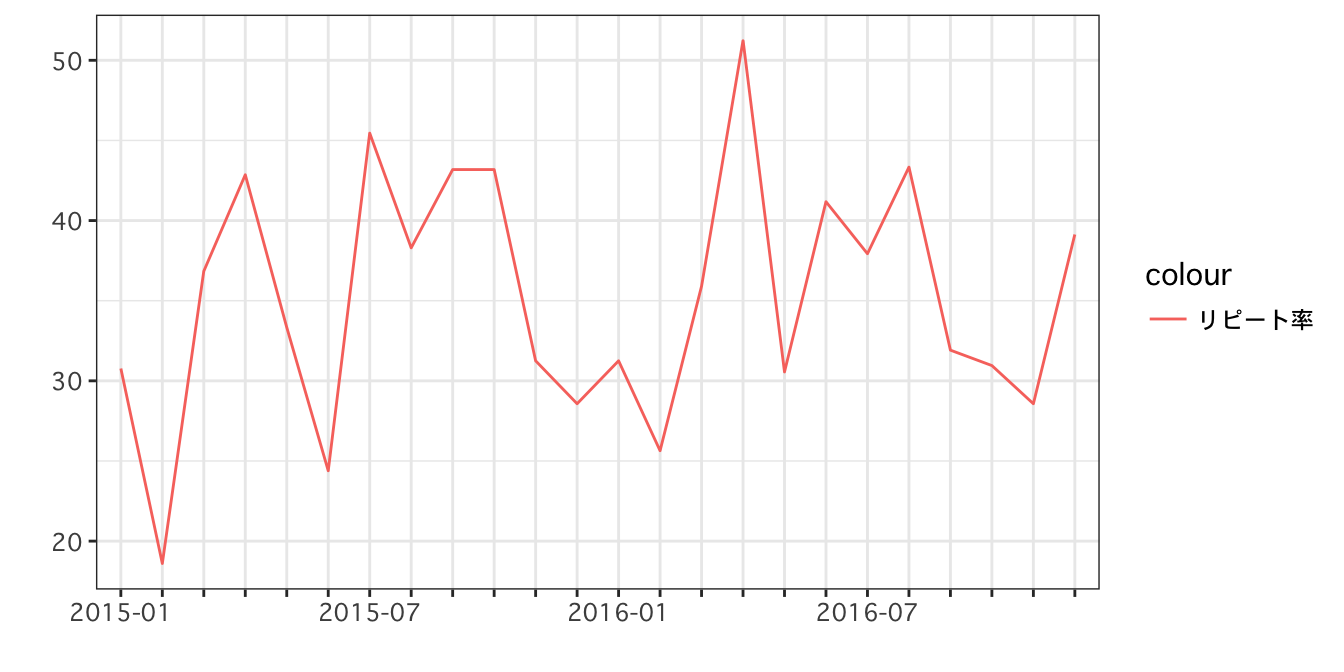
リピート率(ターゲット)の月ごとの推移
30から40 %付近を推移しているようです。
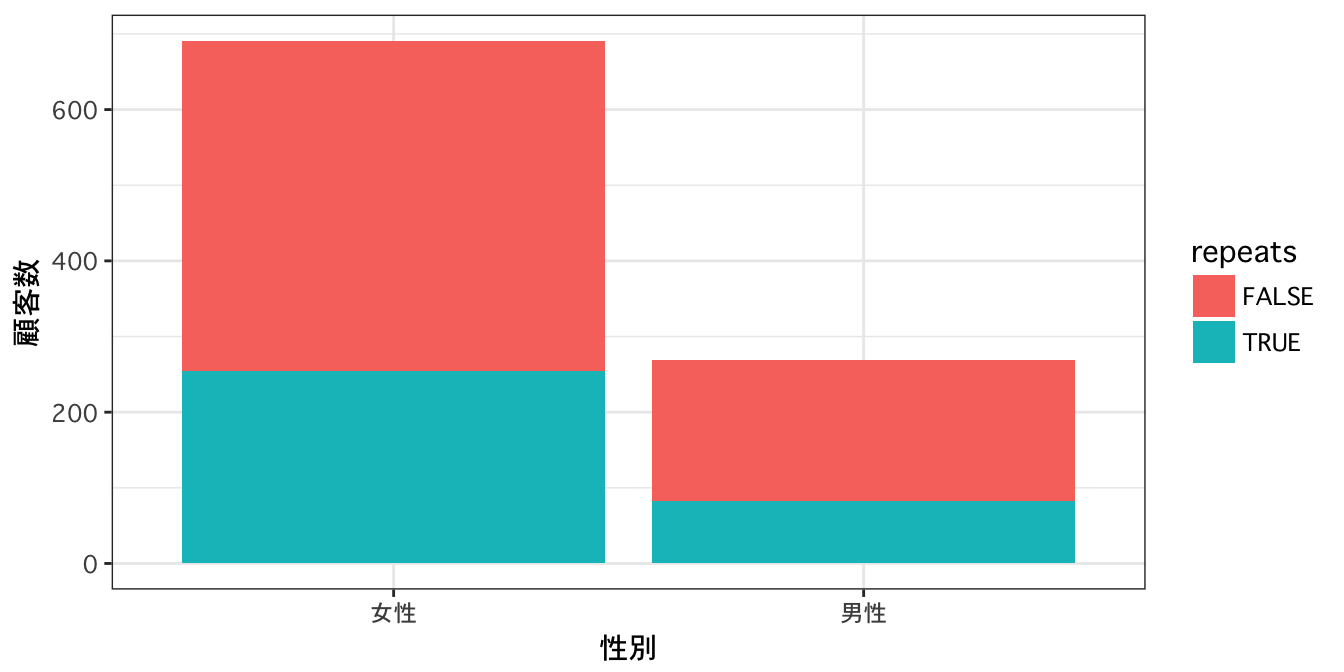
顧客層別リピート率
性別:
- 女性客の方が男性客より多いことがわかります。
年齢層別:
- 年齢不明が約半をしめるのでデータとしての信頼度が低い点に留意する必要があります。
- 20、30代の顧客が多いが、リピート率は低いことがわかります。
