Case9. 品質検査にかかる時間を予測する
- モデリング
実際にランダムフォレストを使って、品質検査にかかる時間予測モデルを作成していきます。
フロー
- データセットの作成
- モデル作成用、検証用にデータセットを分離
- モデル作成用のデータセットでモデリング
- モデルでの予測値(検証用データの各要因をモデルに適用した結果)と検証用データの比較
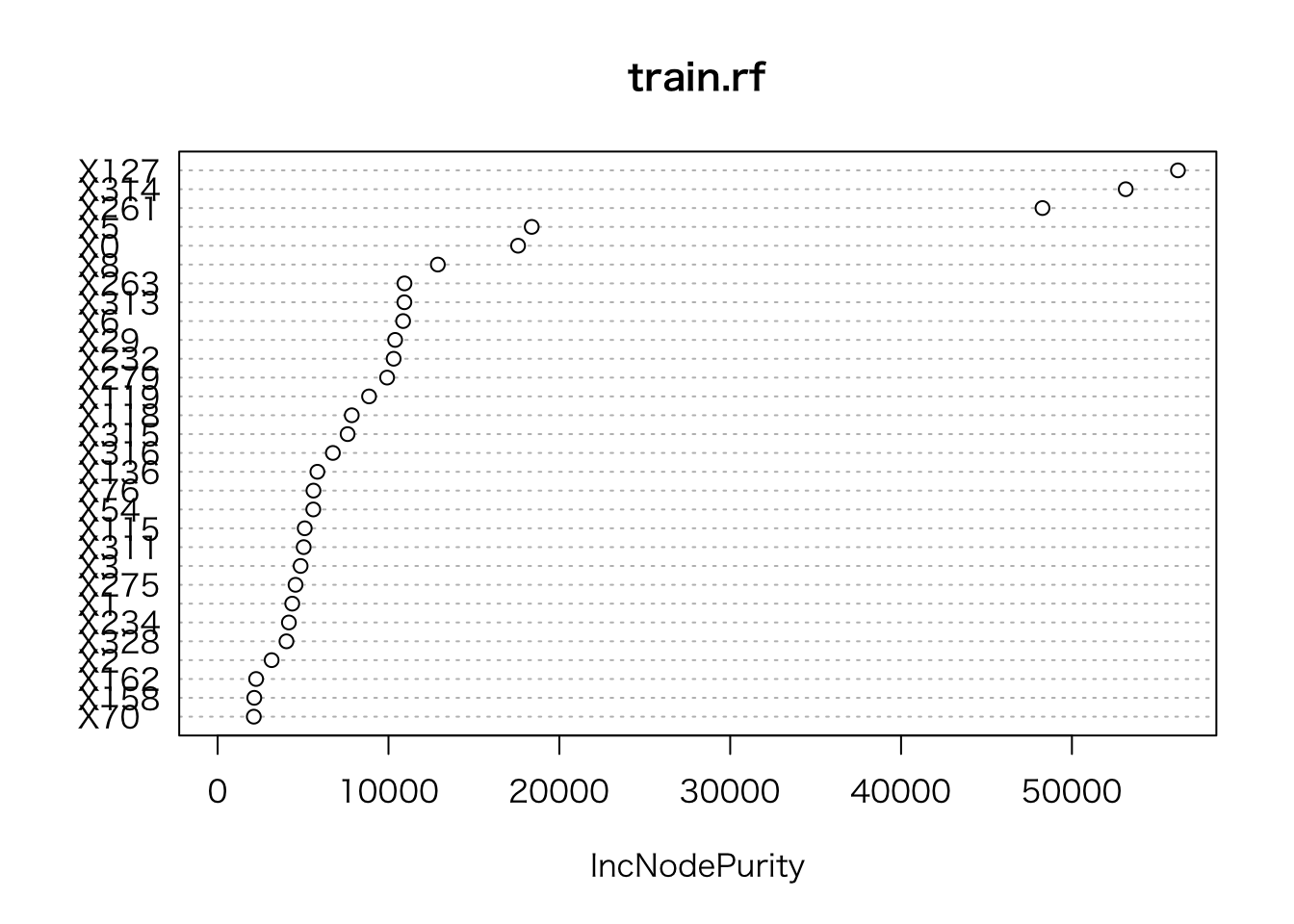
- モデル内容
参考:
https://www.kaggle.com/wti200/xgboost-with-one-hot-encoding-r
https://www.kaggle.com/rsakata/xgboost-private-lb-0-55290
# ライブラリの読み込み
library(data.table)
library(dplyr)
library(ggplot2)
library(randomForest)
# データの読み込み
data <- fread("./data/case09_train.csv", showProgress = FALSE, data.table = FALSE)データセットの作成
# IDは除外
data <- select(data, -ID)
# カテゴリデータをダミー変数に置き換え
feature.names <- names(data)[2:ncol(data)]
for (f in feature.names) {
if (class(data[[f]])=="character") {
levels <- unique(c(data[[f]]))
data[[f]] <- as.integer(factor(data[[f]], levels=levels))
}
}
model.dat <- dataデータセットの分離
# トレーニング用にサンプルをランダムに抽出
train.index <- sort(sample(1:nrow(model.dat), size = 3500))
# モデリング用と検証用にデータセットを分離
train <- model.dat[train.index,]
test <- model.dat[-train.index,]モデリング
ランダムフォレストでモデリング
# この処理は時間がかかります
# チューニング
train.tune <- tuneRF(train[,feature.names], train$y, doBest = T)## mtry = 125 OOB error = 82.9232
## Searching left ...
## mtry = 63 OOB error = 80.02744
## 0.03492105 0.05
## Searching right ...
## mtry = 250 OOB error = 85.75405
## -0.03413814 0.05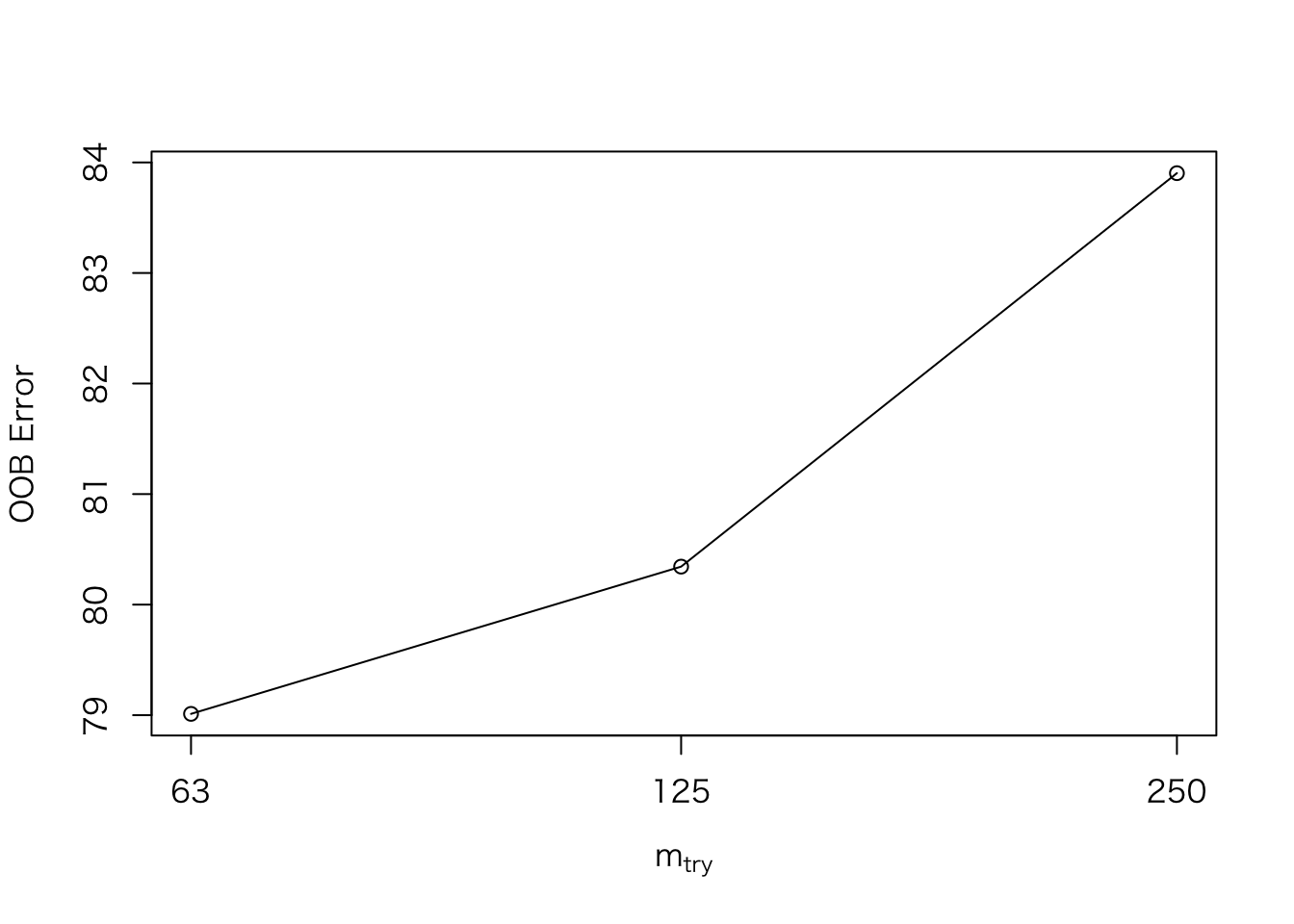
# モデリング
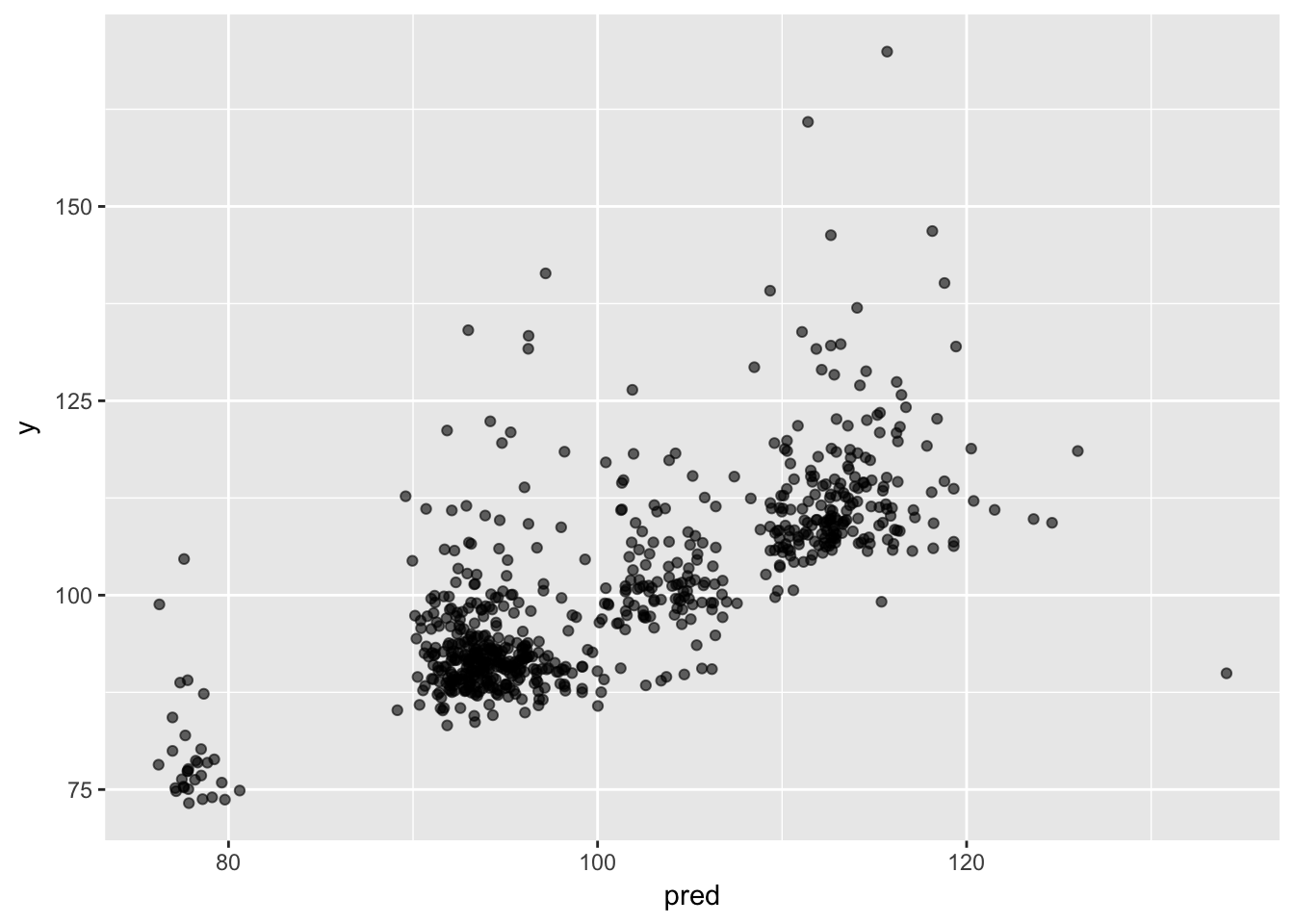
train.rf <- randomForest(y ~., data = train, mtry = train.tune$mtry )モデルの評価(検証用データと予測値の比較)
# 検証用データにモデルを適用
test$pred <- predict(train.rf, test)
ggplot(test, aes(x = pred, y = y)) +
geom_point(alpha = 0.6)