Case9. 品質検査にかかる時間を予測する
- データの理解
与えられたデータを見ていき、現状把握や、品質検査にかかる時間に影響を及ぼす要因を探っていきます。
kaggle data description (データの説明)
- 車のカスタム機能を表すデータセット
- 項目「y」はテストに合格するまでの時間(秒)を表す
- その他の項目内容については不明
ここからは、実際にデータを整理していきます(コード部分に興味のない人はコードは読み飛ばして頂いて結構です)。
参考:
https://www.kaggle.com/msp48731/feature-engineering-and-visualization
https://www.kaggle.com/headsortails/mercedas-update2-intrinsic-noise
準備
# ライブラリの読み込み
library(data.table)
library(dplyr)
library(ggplot2)
# データの読み込み
train <- fread("./data/case09_train.csv", showProgress = FALSE, data.table = FALSE)
### 前処理
# 数値、文字データ項目の分離
train_num <- train[, sapply(train, is.numeric)]
train_char <- train[, sapply(train, is.character)]データ概要
paste0("データ件数:",nrow(train), "件")## [1] "データ件数:4209件"paste0("項目数:", " 数値型:", ncol(train_num), " 文字型:", ncol(train_char))## [1] "項目数: 数値型:370 文字型:8"ただし、数値型は0 or 1なのでダミー変数だと考えられます。
品質検査にかかる時間
ggplot(train,aes(x = y)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.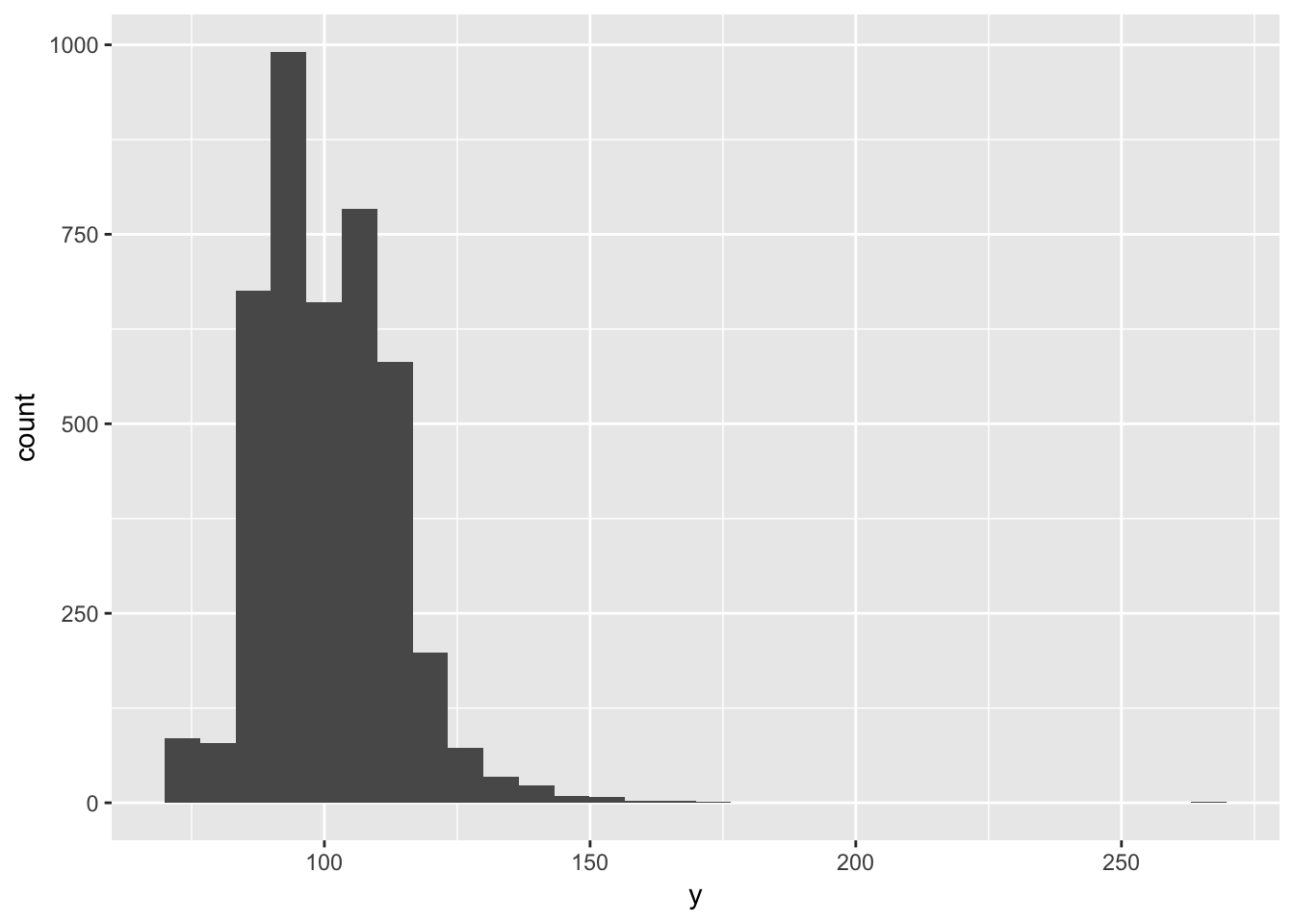
単位は不明ですが、80から120がボリュームゾーンです。
項目ごとのユニークな値数
data.frame(labels = as.factor(names(train_char)),
count = apply(train_char, 2, function(x) length(unique(x)))) %>%
ggplot(aes(x = reorder(labels,count), y = count)) +
geom_bar(stat = "identity")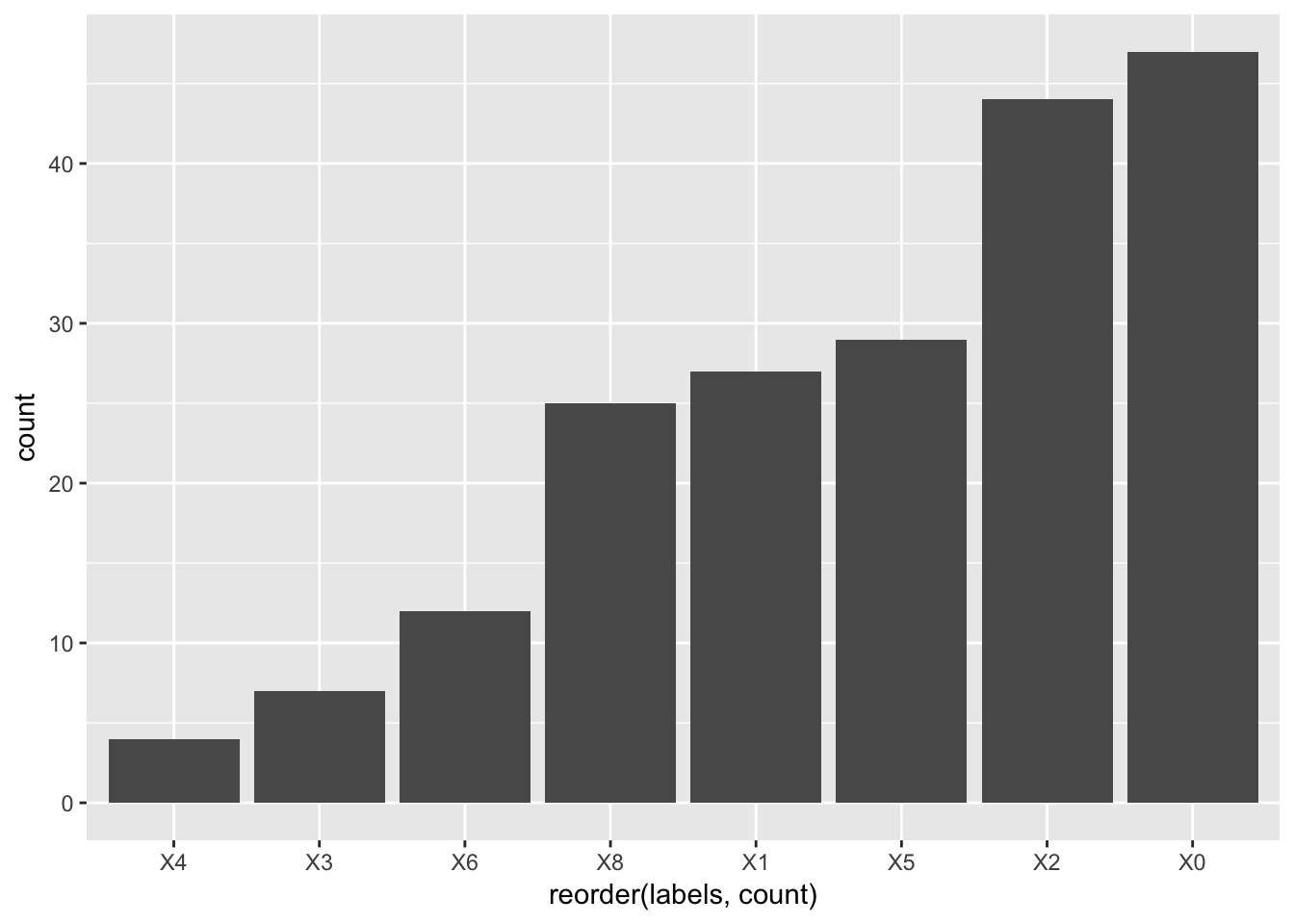
20種類以上のカテゴリ分けされている項目が5つあります。
まとめ
- データ件数:4209件、項目数: 378 (予測対象y以外の項目はカテゴリ)
- 予測対象y(品質検査にかかる時間)のボリュームゾーンは80から120
- 20種類以上のカテゴリ分けされている項目が5つある