Case8. クレームの重要度を予測する
- データの理解
与えられたデータについて見ていき、現状把握や、クレームの重要度に影響を及ぼす要因を探っていきます。
kaggle data description (データの説明)
- 保険請求のデータセット
- その他の項目についての説明なし
ここからは、実際にデータを整理していきます(コード部分に興味のない人はコードは読み飛ばして頂いて結構です)。
参考:https://www.kaggle.com/dmi3kno/allstate-eda
準備
# ライブラリの読み込み
library(data.table)
library(dplyr)
library(ggplot2)
library(corrplot)
# データの読み込み
train <- fread("./data/case08_train.csv", showProgress = FALSE, data.table = FALSE)
### 前処理
# 数値、文字データ項目の分離
train_num <- train[, sapply(train, is.numeric)]
train_char <- train[, sapply(train, is.character)]データ概要
paste0("データ件数:",nrow(train), "件")## [1] "データ件数:188318件"paste0("項目数:", " 数値型:", ncol(train_num), " 文字型:", ncol(train_char))## [1] "項目数: 数値型:16 文字型:116"loss(予測対象)
項目lossが予測対象になっていることから、クレーム処理にかかったコストだと推測されます。
ggplot(train,aes(x = loss)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.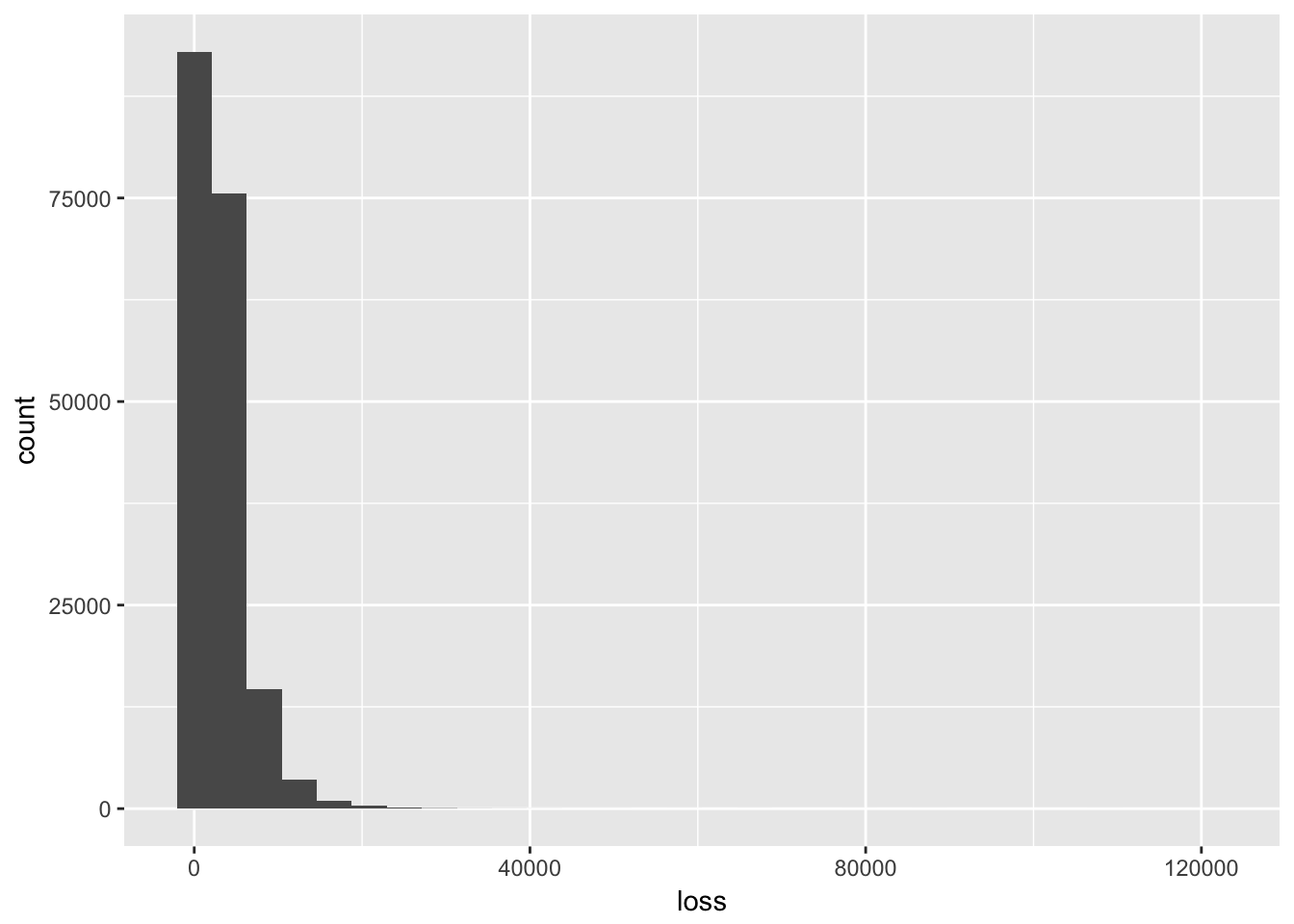
5000未満に絞り込み
filter(train, loss < 5000) %>%
ggplot(aes(x = loss)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
1000から2000がボリュームゾーンのようです。
数値データ
select(train_num, -id) %>%
cor() %>%
corrplot(method="square", order="hclust")
lossと直接相関のある変数はありません。
まとめ
- データ件数:188318件
- 項目数: 数値型:16 文字型:116
- 予測対象loss(クレーム処理のコスト)ボリュームゾーンは1000から2000
- lossと直接相関のある数値型の項目はない