Case3. 需要を予測する
- モデリング
実際にランダムフォレストを使って、需要予測モデルを作成していきます。
フロー
- データセットの作成
- モデル作成用、検証用にデータセットを分離
- モデル作成用のデータセットでモデリング
- モデルでの予測値(検証用データの各要因をモデルに適用した結果)と検証用データの比較
- モデル内容
# ライブラリの読み込み
library(data.table)
library(dplyr)
library(stringr)
library(ggplot2)
library(randomForest)
library(lubridate)
# データの読み込み
data <- fread("./data/case03_train.csv", showProgress = FALSE, data.table = FALSE)データセットの作成
### データセットの作成
model.dat <- data.frame(
count = data$count,
season = factor(data$season, labels = c("Spring", "Summer", "Fall", "Winter")),
holiday = factor(data$holiday),
workingday = factor(data$workingday),
weather = factor(data$weather, labels = c("Good", "Normal", "Bad", "Very Bad")),
temp = data$temp,
atemp = data$atemp,
humidity = data$humidity,
windspeed = data$windspeed,
hour = factor(hour(ymd_hms(data$datetime))),
year = factor(substr(data$datetime, 1, 4))
)データセットの分離
# トレーニング用に7000サンプルをランダムに抽出
train.index <- sort(sample(1:nrow(model.dat), size = 7000))
#モデリング用と検証用にデータセットを分離
train <- model.dat[train.index,]
test <- model.dat[-train.index,]モデリング
ランダムフォレストでモデリング
# この処理は時間がかかります
# チューニング
train.tune <- tuneRF(train[, -1], train[, 1], doBest = T)## mtry = 3 OOB error = 3939.453
## Searching left ...
## mtry = 2 OOB error = 5258.079
## -0.3347231 0.05
## Searching right ...
## mtry = 6 OOB error = 2596.741
## 0.3408371 0.05
## mtry = 10 OOB error = 2405.369
## 0.07369697 0.05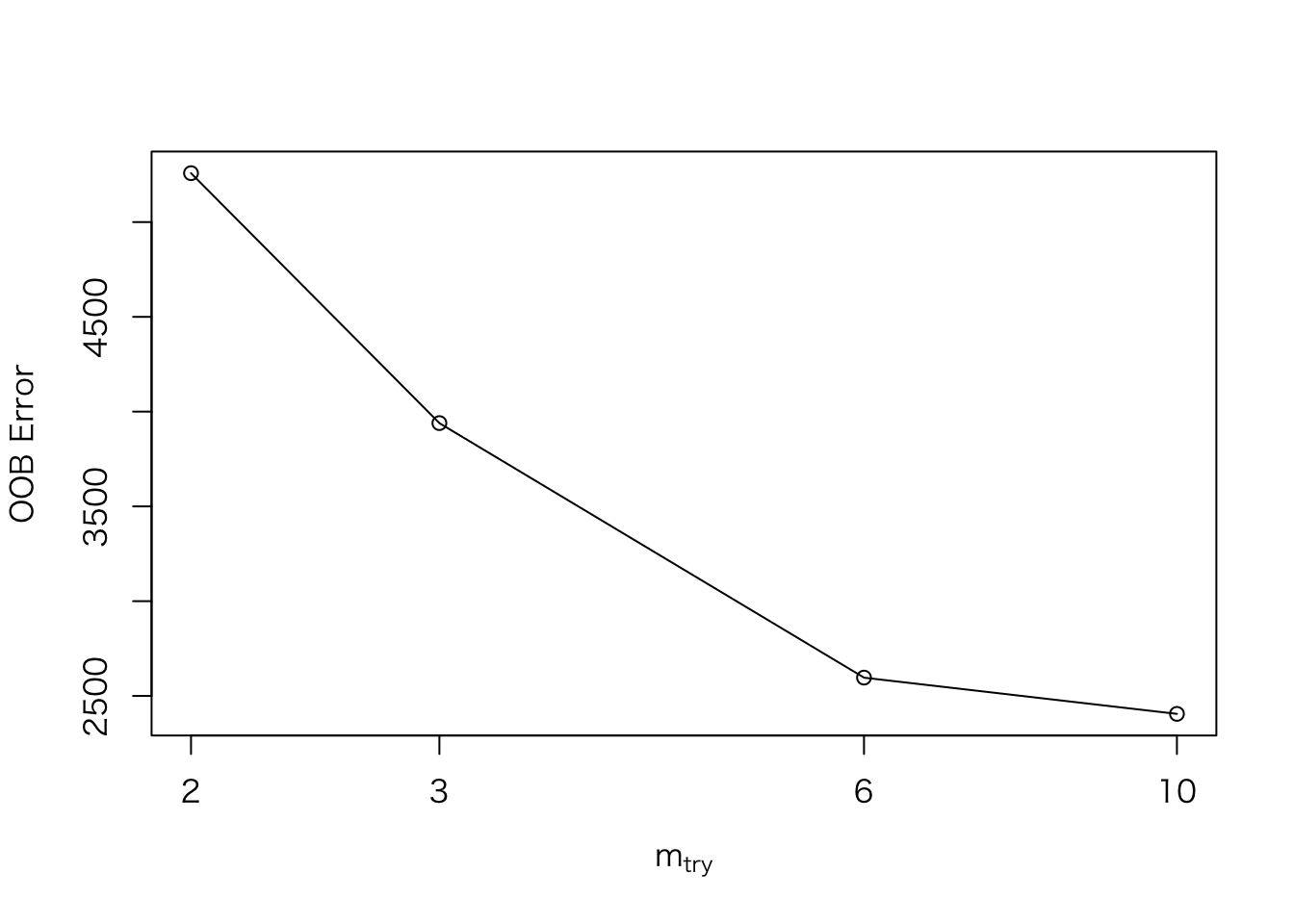
# モデリング
train.rf <- randomForest(count ~., data = train, mtry = train.tune$mtry)モデルの評価(検証用データと予測値の比較)
# 検証用データにモデルを適用
test$pred <- predict(train.rf, test)
# 平均二乗誤差(検証用データのレンンタル数と予測値の離れ具合)でモデル精度を評価
(mean((test$count - test$pred) ^ 2)) ^ 1/2## [1] 1020.105この数値はいろいろなパターンでモデルを作成し、比較する際に使う。
ggplot(test, aes(x = pred, y = count)) +
geom_point(alpha = 0.6)
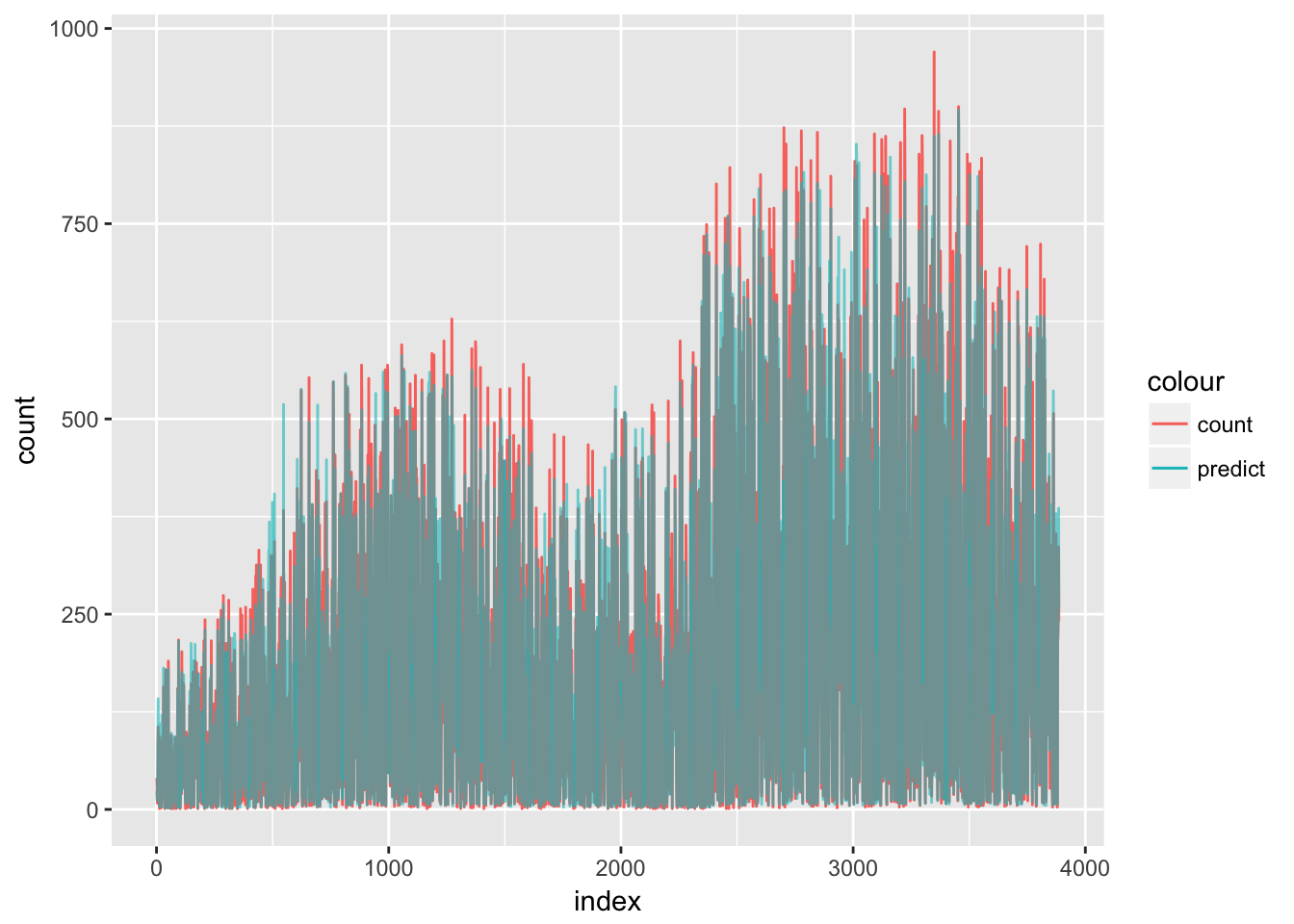
横軸が予測値で、縦軸が検証用データのレンタル数です。それなりに予測できているようです。
test$index <- 1:nrow(test)
ggplot(test, aes(x = index)) +
geom_line(aes(y = count, colour = "count")) +
geom_line(aes(y = pred, colour = "predict"), alpha = 0.6)