Case1. 注文を予測する
- モデリング
実際にランダムフォレストを使って、注文予測モデルを作成していきます。
フロー
- データセットの作成
- モデル作成用、検証用にデータセットを分離
- モデル作成用のデータセットでモデリング
- モデルでの予測値(検証用データの各要因をモデルに適用した結果)と検証用データの比較
- モデル内容
参考
https://www.kaggle.com/cjansen/instacart-xgboost-starter-lb-0-3808482/code
# ライブラリの読み込み
library(data.table)
library(dplyr)
library(ggplot2)
library(randomForest)
# データの読み込み
orders <- fread('./data/case02_orders.csv', showProgress = FALSE, data.table = FALSE)
products <- fread('./data/case02_products.csv', showProgress = FALSE, data.table = FALSE)
ordert <- fread('./data/case02_order_products__train.csv', showProgress = FALSE, data.table = FALSE)
orderp <- fread('./data/case02_order_products__prior.csv', showProgress = FALSE, data.table = FALSE)
aisles <- fread('./data/case02_aisles.csv', showProgress = FALSE, data.table = FALSE)
departments <- fread('./data/case02_departments.csv', showProgress = FALSE, data.table = FALSE)データセットの作成
# 前処理
aisles$aisle <- as.factor(aisles$aisle)
departments$department <- as.factor(departments$department)
orders$eval_set <- as.factor(orders$eval_set)
products$product_name <- as.factor(products$product_name)
products <- products %>%
inner_join(aisles) %>%
inner_join(departments) %>%
select(-aisle_id, -department_id)
ordert$user_id <- orders$user_id[match(ordert$order_id, orders$order_id)]
orders_products <- inner_join(orders, orderp, by = "order_id")
# 商品
prd <- orders_products %>%
arrange(user_id, order_number, product_id) %>%
group_by(user_id, product_id) %>%
mutate(product_time = row_number()) %>%
ungroup() %>%
group_by(product_id) %>%
summarise(
prod_orders = n(),
prod_reorders = sum(reordered),
prod_first_orders = sum(product_time == 1),
prod_second_orders = sum(product_time == 2)
)
prd$prod_reorder_probability <- prd$prod_second_orders / prd$prod_first_orders
prd$prod_reorder_times <- 1 + prd$prod_reorders / prd$prod_first_orders
prd$prod_reorder_ratio <- prd$prod_reorders / prd$prod_orders
prd <- select(prd, -prod_reorders, -prod_first_orders, -prod_second_orders)
# ユーザー
users <- orders %>%
filter(eval_set == "prior") %>%
group_by(user_id) %>%
summarise(
user_orders = max(order_number),
user_period = sum(days_since_prior_order, na.rm = T),
user_mean_days_since_prior = mean(days_since_prior_order, na.rm = T)
)
us <- orders_products %>%
group_by(user_id) %>%
summarise(
user_total_products = n(),
user_reorder_ratio = sum(reordered == 1) / sum(order_number > 1),
user_distinct_products = n_distinct(product_id)
)
users <- inner_join(users, us)
users$user_average_basket <- users$user_total_products / users$user_orders
us <- orders %>%
filter(eval_set != "prior") %>%
select(user_id, order_id, eval_set,
time_since_last_order = days_since_prior_order)
users <- inner_join(users, us)
# データセット
data <- orders_products %>%
group_by(user_id, product_id) %>%
summarise(
up_orders = n(),
up_first_order = min(order_number),
up_last_order = max(order_number),
up_average_cart_position = mean(add_to_cart_order))
data <- data %>%
inner_join(prd, by = "product_id") %>%
inner_join(users, by = "user_id")
data$up_order_rate <- data$up_orders / data$user_orders
data$up_orders_since_last_order <- data$user_orders - data$up_last_order
data$up_order_rate_since_first_order <- data$up_orders / (data$user_orders - data$up_first_order + 1)
data <- data %>%
left_join(ordert %>% select(user_id, product_id, reordered),
by = c("user_id", "product_id"))
model.dat <- as.data.frame(data[data$eval_set == "train",])
model.dat$eval_set <- NULL
model.dat$user_id <- NULL
model.dat$product_id <- NULL
model.dat$order_id <- NULL
model.dat$reordered[is.na(model.dat$reordered)] <- 0データセットの分離
# すべてのデータを使うと時間がかかるので調整
model.dat <- model.dat[1:100000,]
# トレーニング用に70000サンプルをランダムに抽出
train.index <- sort(sample(1:nrow(model.dat), size = 70000))
#モデリング用と検証用にデータセットを分離
train <- model.dat[train.index,]
test <- model.dat[-train.index,]モデリング
ランダムフォレストでモデリング
# この処理は時間がかかります
# チューニング
train.tune <- tuneRF(train[, -20], as.factor(train[, 20]), doBest = T)## mtry = 4 OOB error = 9.81%
## Searching left ...
## mtry = 2 OOB error = 9.72%
## 0.008741259 0.05
## Searching right ...
## mtry = 8 OOB error = 9.82%
## -0.001748252 0.05
# モデリング
train.rf <- randomForest(as.factor(reordered) ~., data = train, mtry = train.tune$mtry )モデルの評価(検証用データと予測値の比較)
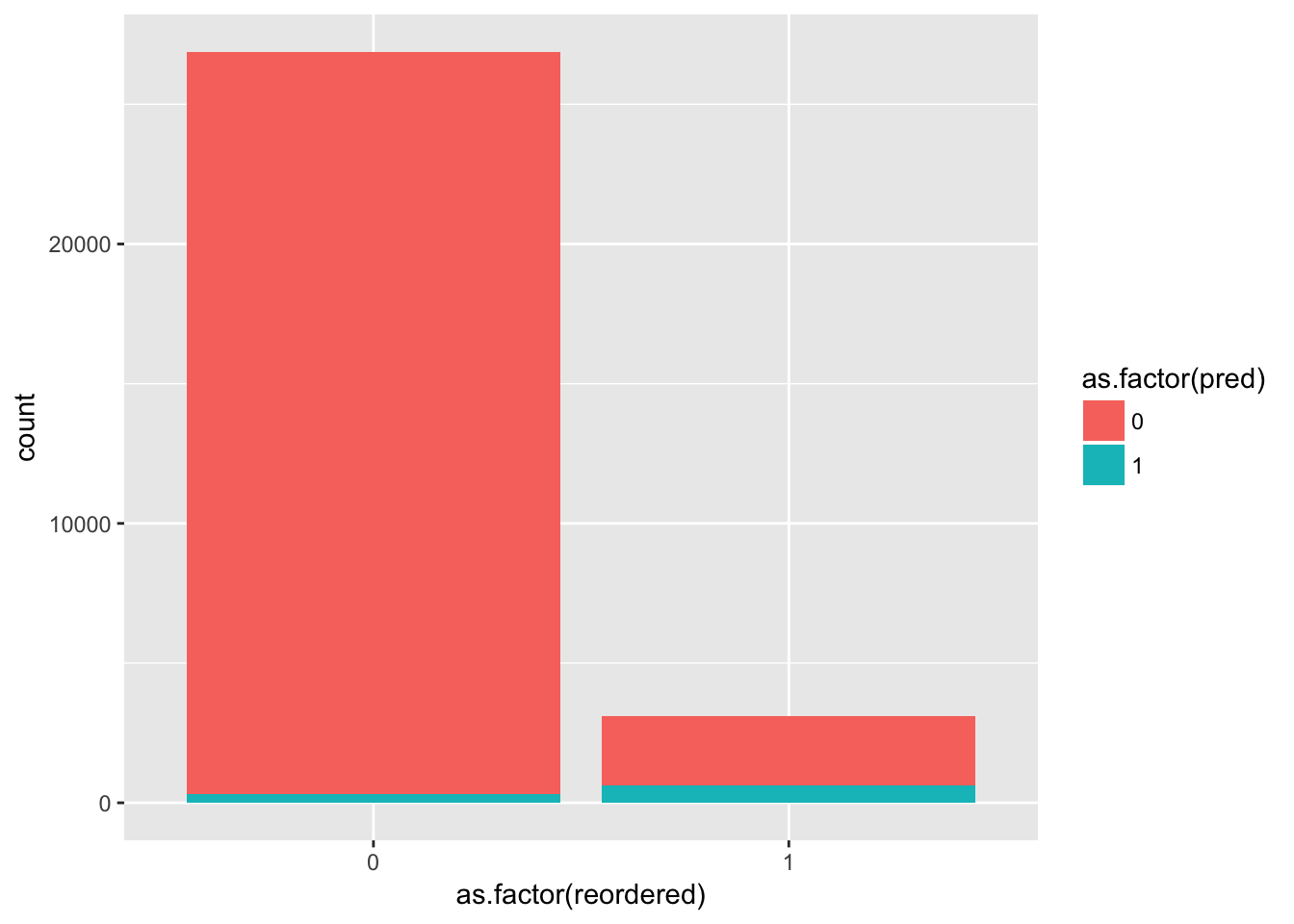
# 検証用データにモデルを適用
test$pred <- predict(train.rf, test)
group_by(test,pred,reordered) %>%
summarise(count = n()) %>%
ggplot(aes(x = as.factor(reordered), y = count, fill = as.factor(pred))) +
geom_bar(stat = "identity")