Case7. 価格(相場)を予測する
- データの理解
与えられたデータについて見ていき、現状把握や、商品価格に影響を及ぼす要因を探っていきます。
kaggle data description (データの説明)
- train_id or test_id:id
- name:タイトル
- item_condition_id:商品のコンディション(5段階評価)
- category_name:商品カテゴリー(3階層)
- brand_name:ブランド
- price:価格
- shipping:発送料(0:売り手負担、1:買い手負担)
- item_description:商品についての説明記述
ここからは、実際にデータを整理していきます(コード部分に興味のない人はコードは読み飛ばして頂いて結構です)。
参考:https://www.kaggle.com/captcalculator/a-very-extensive-mercari-exploratory-analysis
準備
# ライブラリの読み込み
library(data.table)
library(dplyr)
library(stringr)
library(ggplot2)
# データの読み込み
train <- fread("./data/case07_train.tsv", showProgress = FALSE, data.table = FALSE)データ概要
dim(train)## [1] 1482535 81482535 件のデータがあるようです。
ターゲットデータ(価格)
予測対象のpriceを見ていきます。
summary(train$price)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.00 10.00 17.00 26.74 29.00 2009.00最低価格に0円が含まれているため、対象データから取り除きます。
train <- filter(train, price != 0) # 価格が0の商品をデータから取り除く
summary(train$price)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 3.00 10.00 17.00 26.75 29.00 2009.00中央値が17ドル、平均値が26.8ドルの商品が取引されているようです。
価格帯の分布
ggplot(train, aes(x = price)) +
geom_histogram() 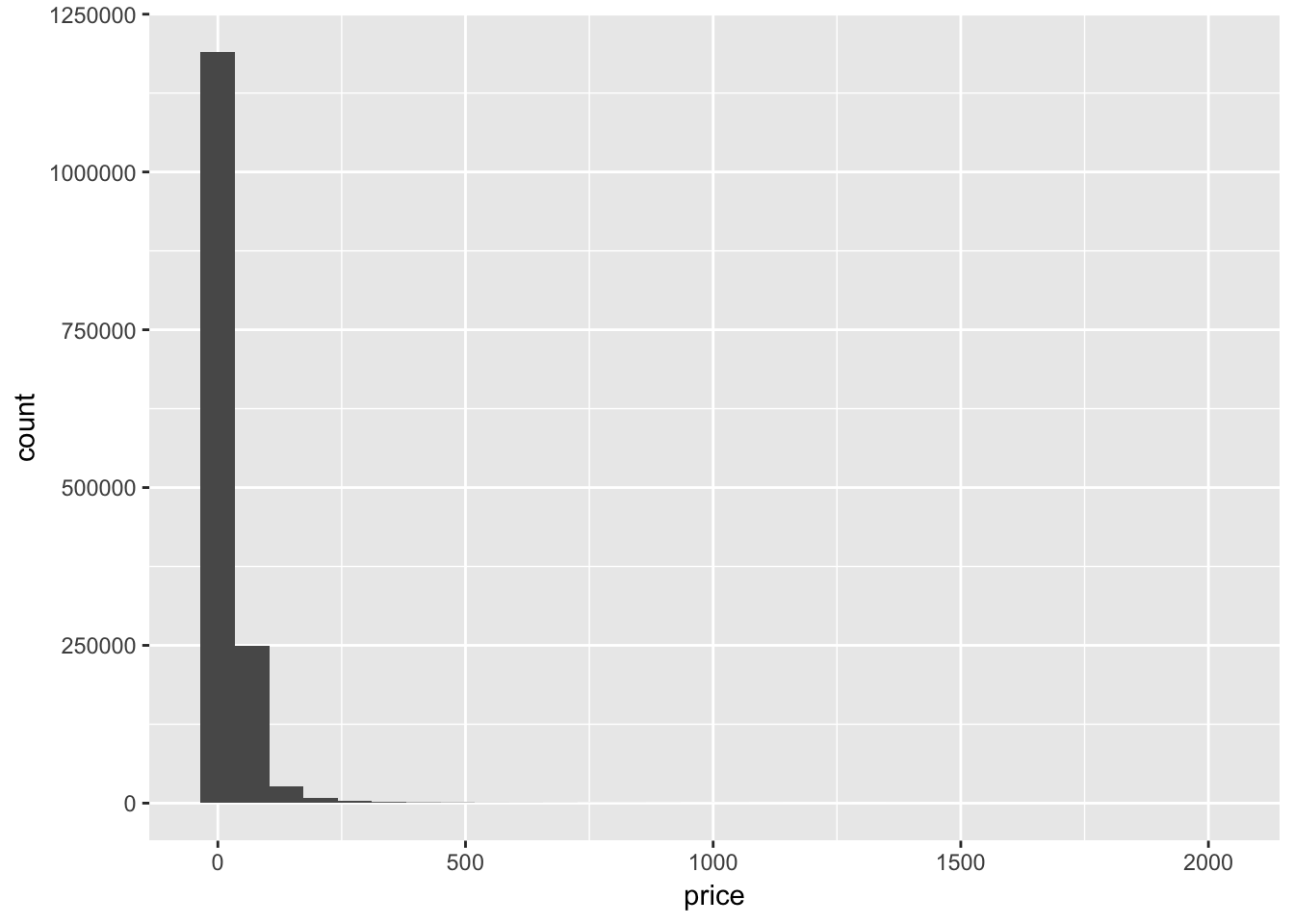
大半が100ドル未満のようなので、100ドル未満の分布について見てみましょう。
価格帯(100ドル未満)の分布
filter(train, price < 100) %>%
ggplot(aes(x = price)) +
geom_histogram() 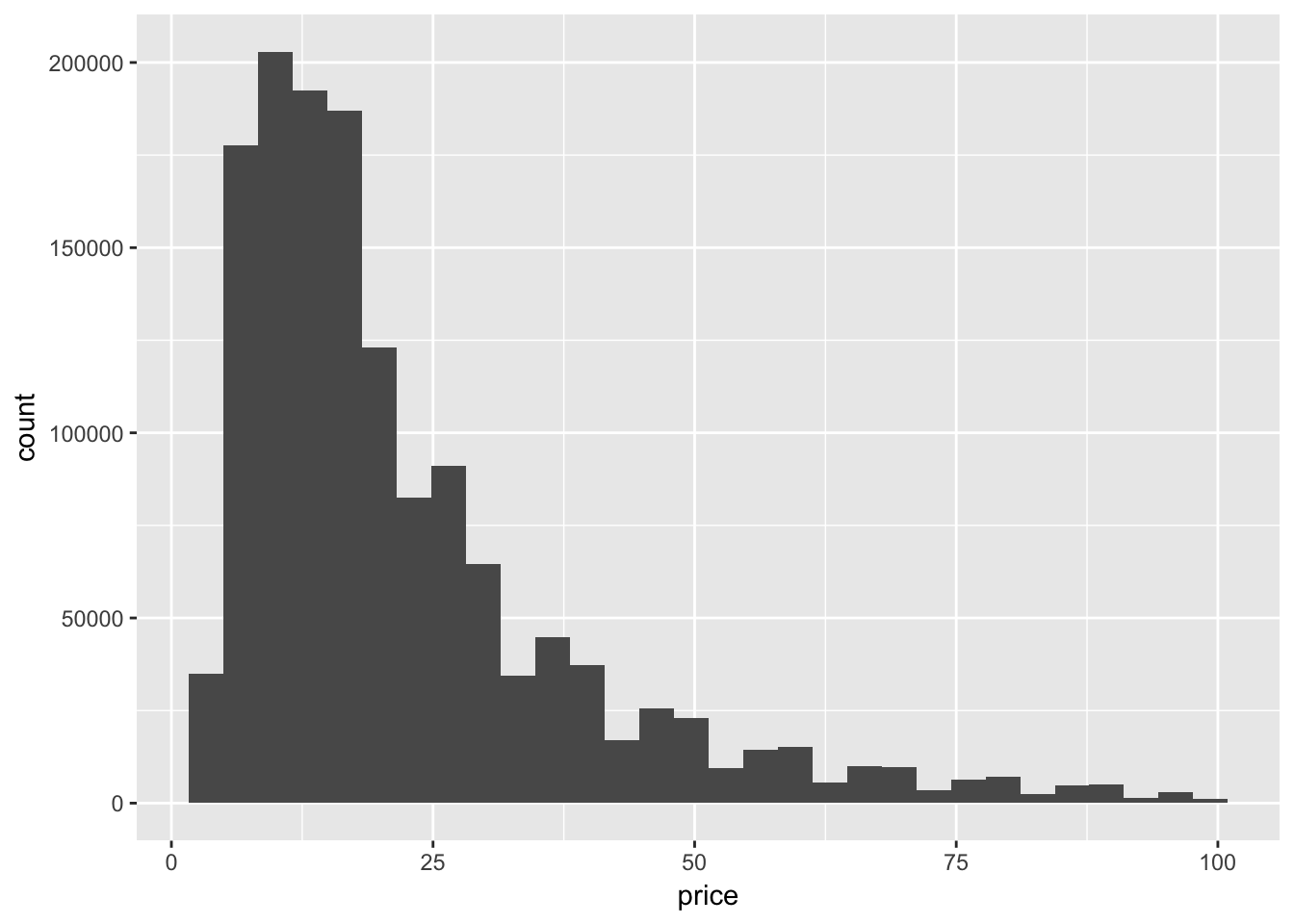
商品の価格帯は約10から25ドル付近に集中しているようです。
商品コンディション
コンディションは5段階評価されています。コンディションごとの商品数についてみると、コンディション1から3の商品が大半を占めるようです。
table(train$item_condition_id) %>%
as.data.frame() %>%
ggplot(aes(x = Var1, y = Freq / 1000)) +
geom_bar(stat = 'identity') +
labs(x = "Item Condition", y = "Number of items (000s)")
filter(train, price < 100) %>%
ggplot(aes(x = as.factor(item_condition_id), y = price)) +
geom_boxplot() +
labs(x = "Item Condition")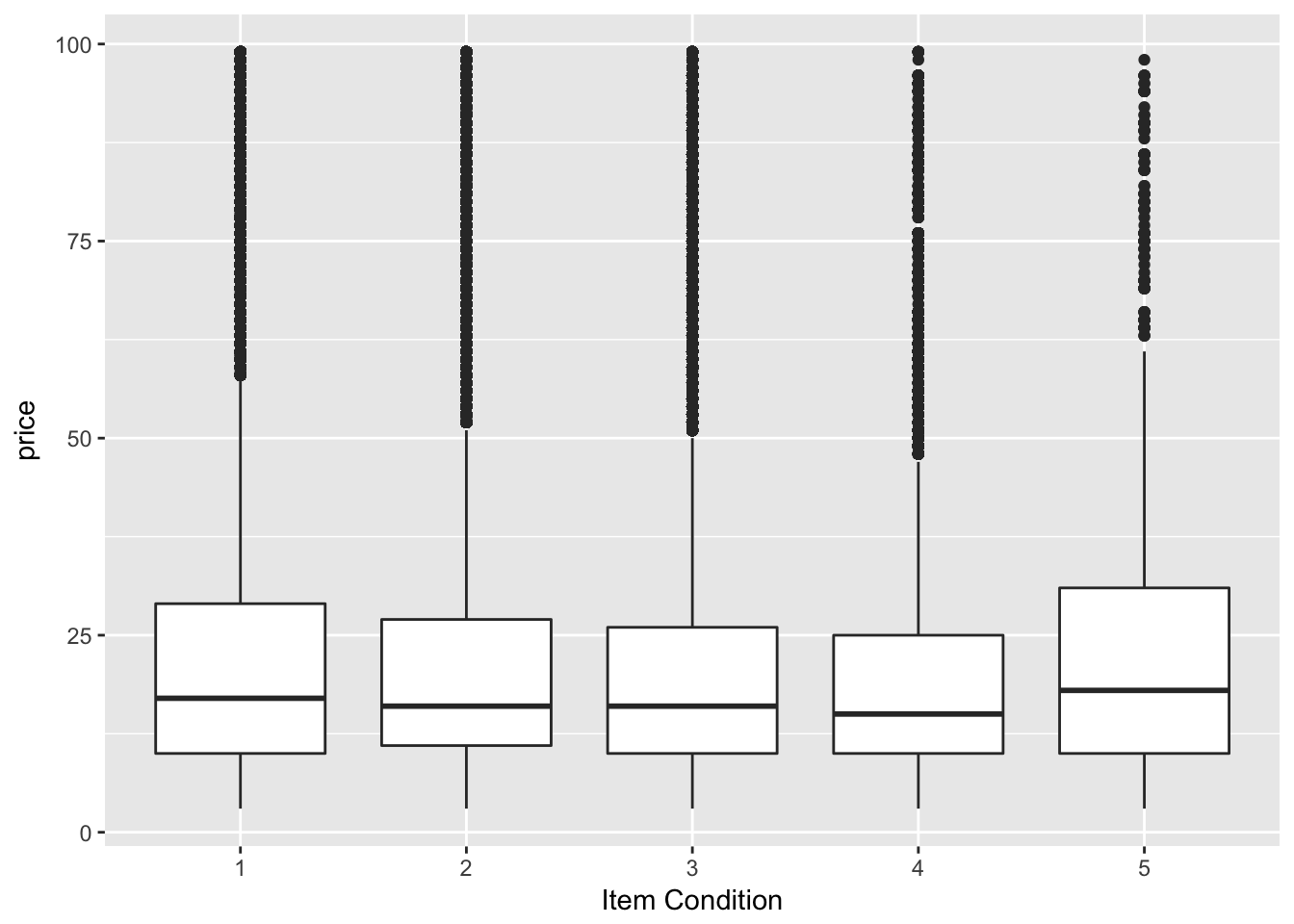
コンディションと価格(100ドル未満)の関係を見ますと、特に関連性はなさそうです。ただし、これはコンディション以外の条件を加味していません(特定のジャンルはコンディションの良いものほど価格が高くなるなど)。つまり、「コンディション単体で価格を予測するのは難しい」ことがわかりました。
商品カテゴリー
商品カテゴリーデータは、「ジャンル1 / ジャンル2 / ジャンル3」のように階層化されています。階層化されたジャンルを分解しそれぞれのレベルごとにデータを見ていきます。
# 3階層構造のカテゴリーを分解し、新たな列として追加
temp <- str_split(train$category_name, pattern = "/")
train$category01 <- sapply(temp, function(x) x[1])
train$category02 <- sapply(temp, function(x) x[2])
train$category03 <- sapply(temp, function(x) x[3])カテゴリーレベル1での商品数(トップ7)
ほぼ女性向けの商品で、一部電化製品やDYI関連が取引されているようです。
sort(table(train$category01), decreasing = TRUE)[1:7] %>%
as.data.frame() %>%
ggplot(aes(x = Var1, y = Freq / 1000)) +
geom_bar(stat = 'identity') +
labs(x = "category level 1", y = "Number of items (000s)")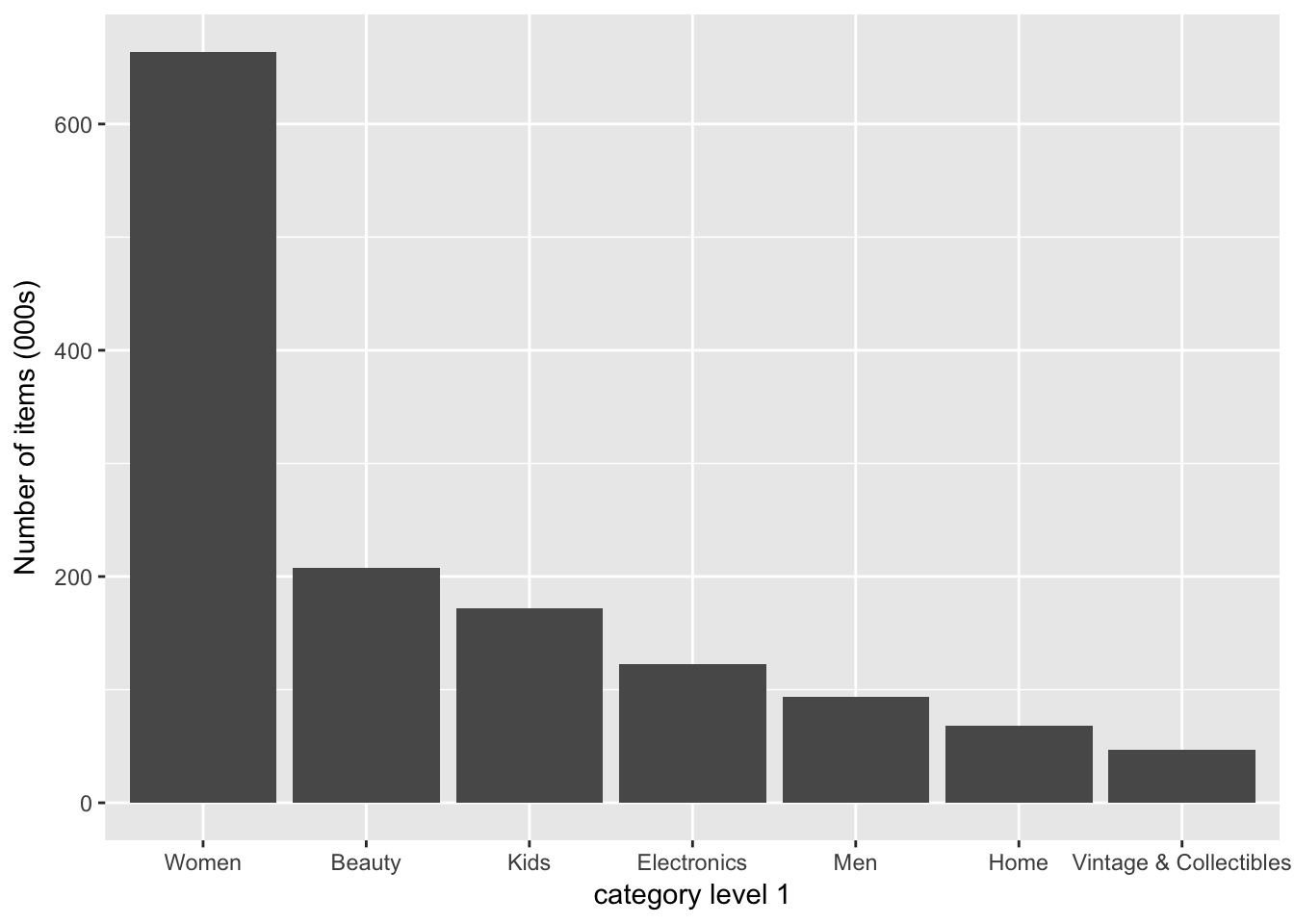
カテゴリーレベル2での商品数(トップ7)
sort(table(train$category02), decreasing = TRUE)[1:7] %>%
as.data.frame() %>%
ggplot(aes(x = Var1, y = Freq / 1000)) +
geom_bar(stat = 'identity') +
labs(x = "category level 2", y = "Number of items (000s)")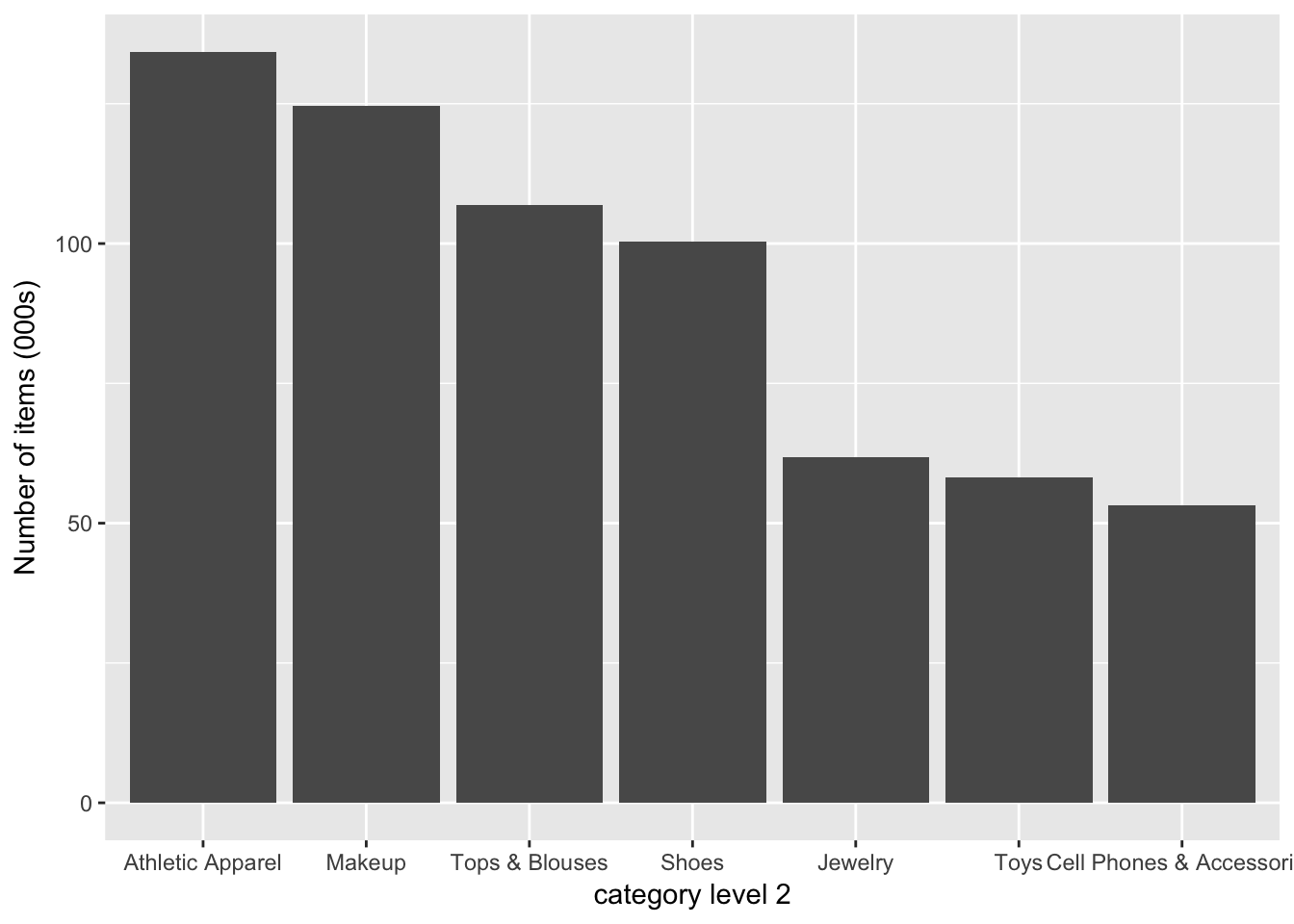
カテゴリーレベル1と価格(100ドル未満)
「カテゴリー単体では価格を予測することは難しい」が見れるかと思います。
filter(train, price < 100) %>%
ggplot(aes(x = category01, y = price)) +
geom_boxplot() +
coord_flip() 
ブランド
価格帯が高いトップ20ブランドの中央値
group_by(train, brand_name) %>%
summarise(median_price = median(price)) %>%
arrange(-median_price) %>%
head(20) %>%
ggplot(aes(x = reorder(brand_name, median_price), y = median_price)) +
geom_point() +
coord_flip() +
labs(x = '', y = 'Median price') 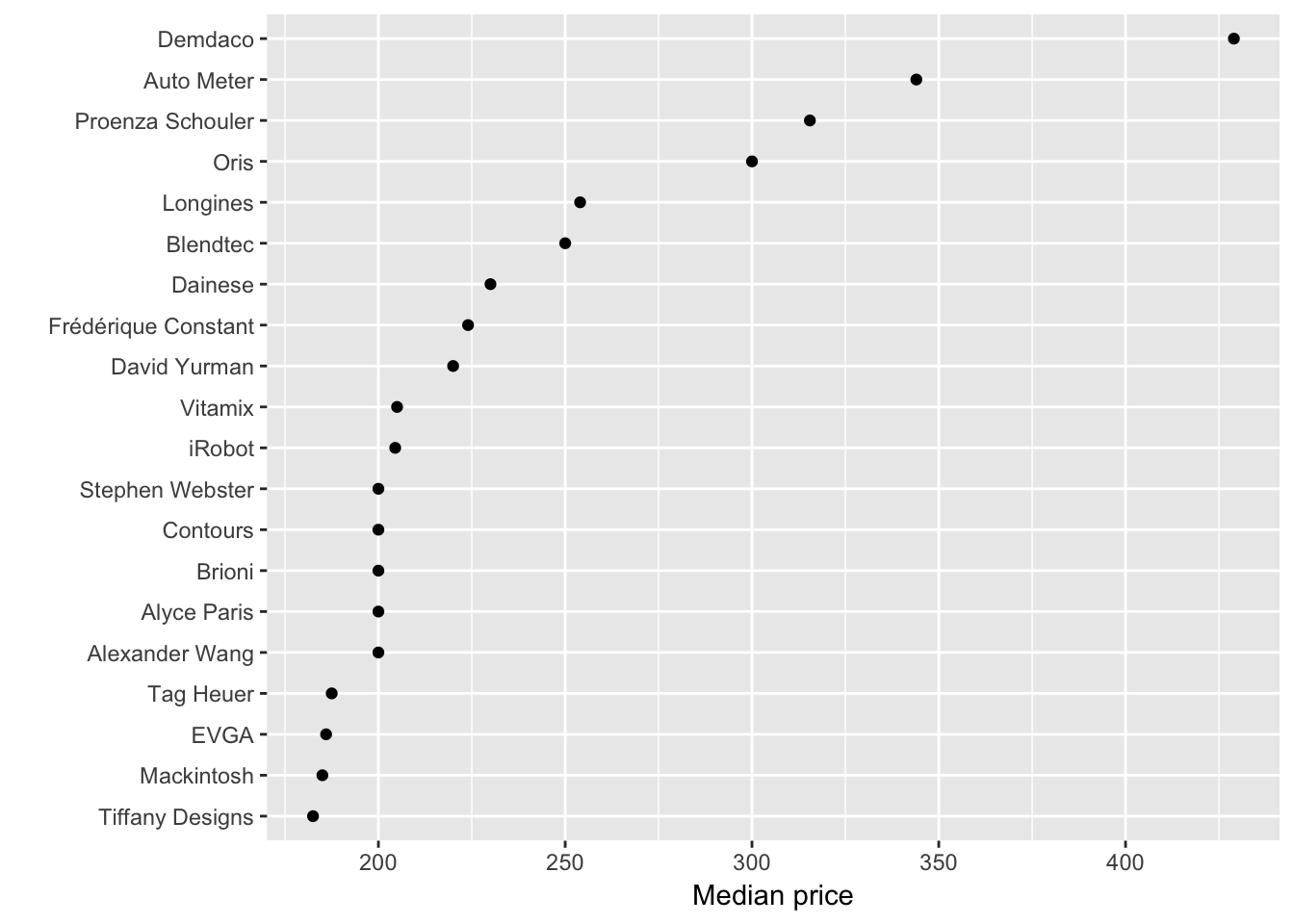
全体の中央値が17ドルに対して、トップ20ははるかに上回っています。ブランドが価格に及ぼす影響は大きそうです。ただし、価格帯の分布からこれらの価格帯の商品は取り扱い数が極端に少ないことに留意してください。
発送料
発送料と価格(100ドル未満)の分布
filter(train, price < 100) %>%
ggplot(aes(x = price, fill = factor(shipping))) +
geom_density(adjust = 2, alpha = 0.6) +
labs(x = 'price', y = "") 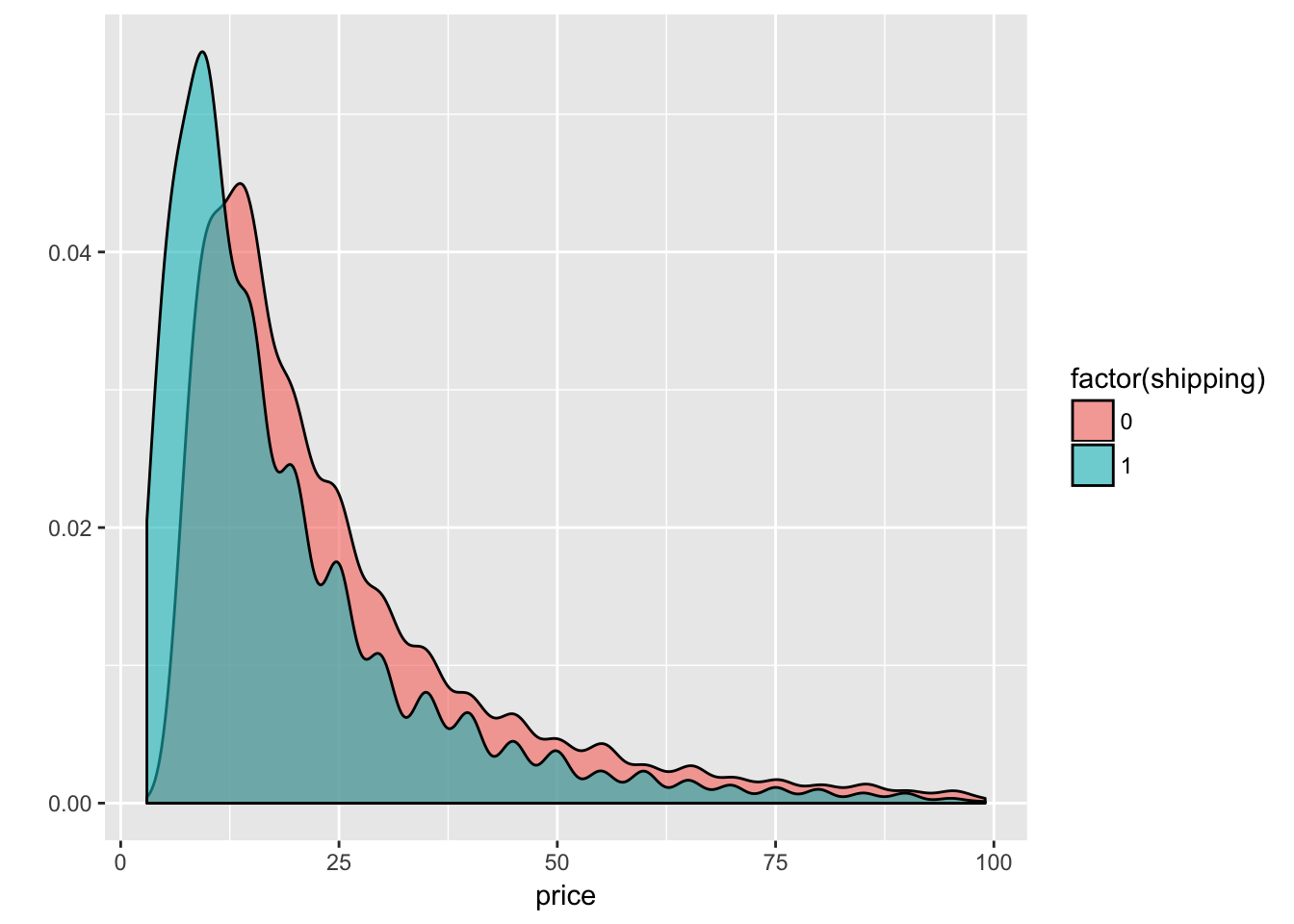
0が売り手負担、1が買い手負担ですので、価格が約10ドルを下回ると買い手負担の割合の方が高くなるようです。発送料をどちらが負担するかは、価格によって決まってくるようです。つまり、価格を予測するモデルに「発送料」は使えないと考えられます(価格予測モデルに使えるのは、価格へ影響を及ぼす要因だけです)。
商品についての説明記述
言語が日本語でないため割愛します(使用するパッケージや関数が日本語と異なるため)。特定のキーワード(ブランド名など)が含まれるかどうかといった形で、予測モデルの作成に使用します。
変数間の関連
カテゴリーレベル1でのコンディションと価格
group_by(train, category01, item_condition_id) %>%
summarise(median_price = median(price)) %>%
ggplot(aes(x = item_condition_id, y = category01, fill = median_price )) +
geom_tile() +
scale_fill_gradient(low = 'lightblue', high = 'cyan4') +
labs(x = 'Condition', y = '', fill = 'Median price') +
theme_bw() +
theme(legend.position = 'bottom')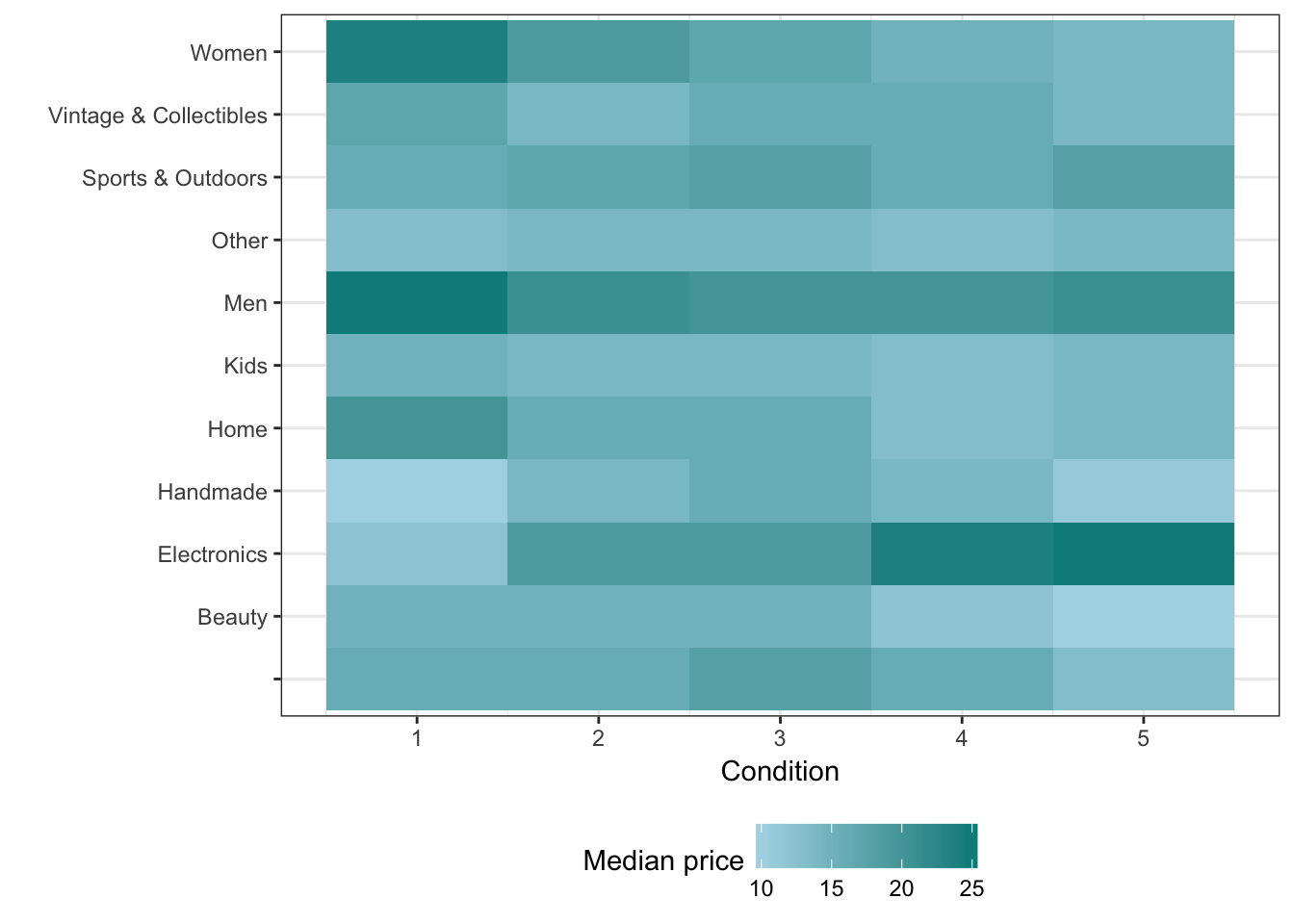
womenではコンディションが低いほど価格が高くなり、Electronics(電化製品)ではコンディションが高いほど価格が高くなることが見られます。つまり、「特定のジャンルかつコンディション」のような複数の要因を同時に見ていくことで価格予測モデル作る必要がありそうです。
まとめ
現状把握
- 商品の価格帯は10から25ドル付近に集中している(中央値17ドル)
- コンディション:5段階評価のうち、1から3が大半を占める
- 商品カテゴリー:ほぼ女性向けの商品で、一部電化製品やDYI関連が取引されている
- ブランド:特定のブランドは商品価格が高い
- 発送料負担:価格が約10ドルを下回ると買い手負担の割合の方が高くなる
モデル作成のための仮説
- 「特定のジャンルかつコンディション」のような複数の要因を同時に加味したモデルが必要
- コンディション、ブランド、商品カテゴリー、商品説明は価格予測に使える